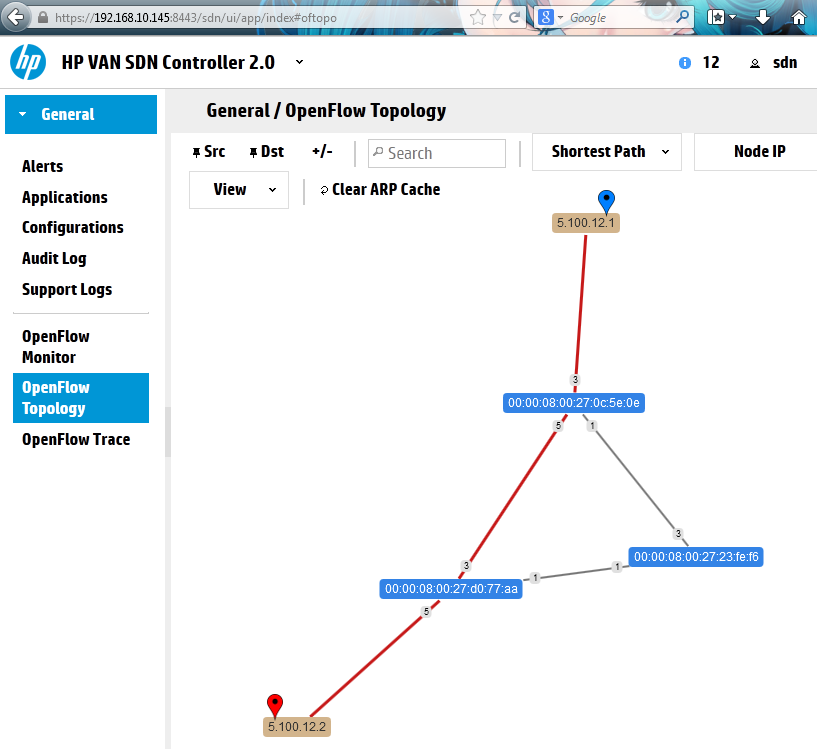
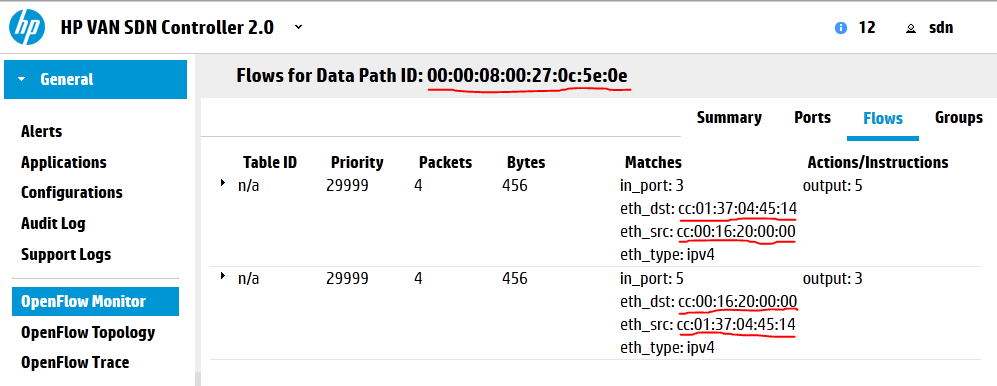
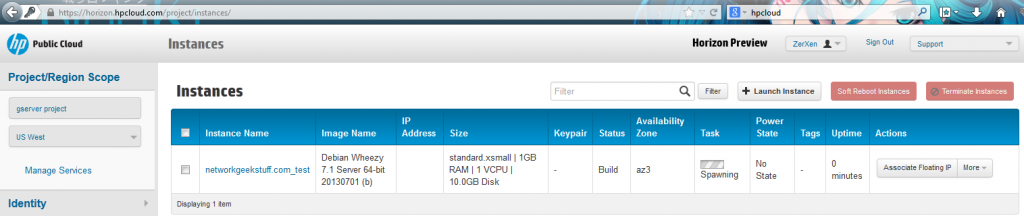
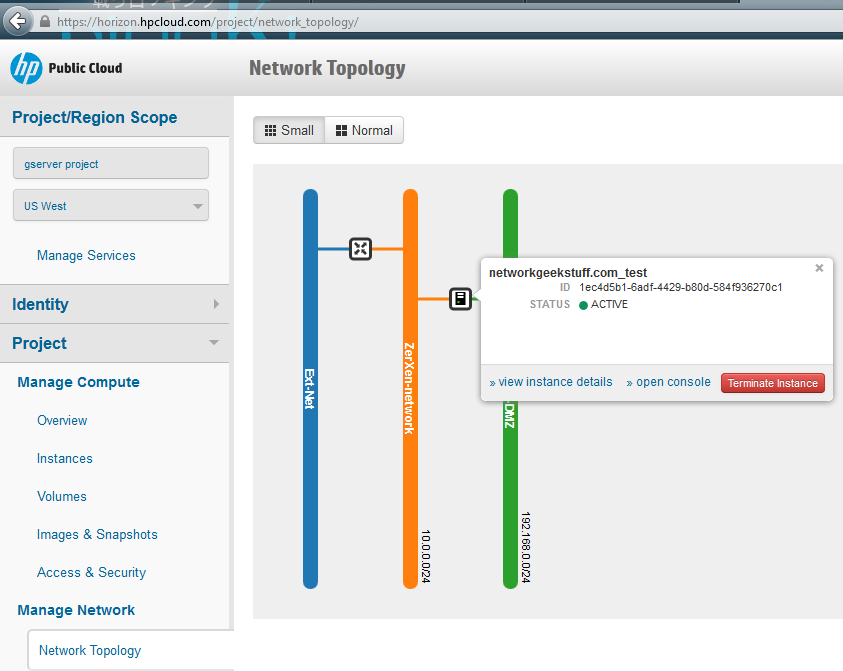
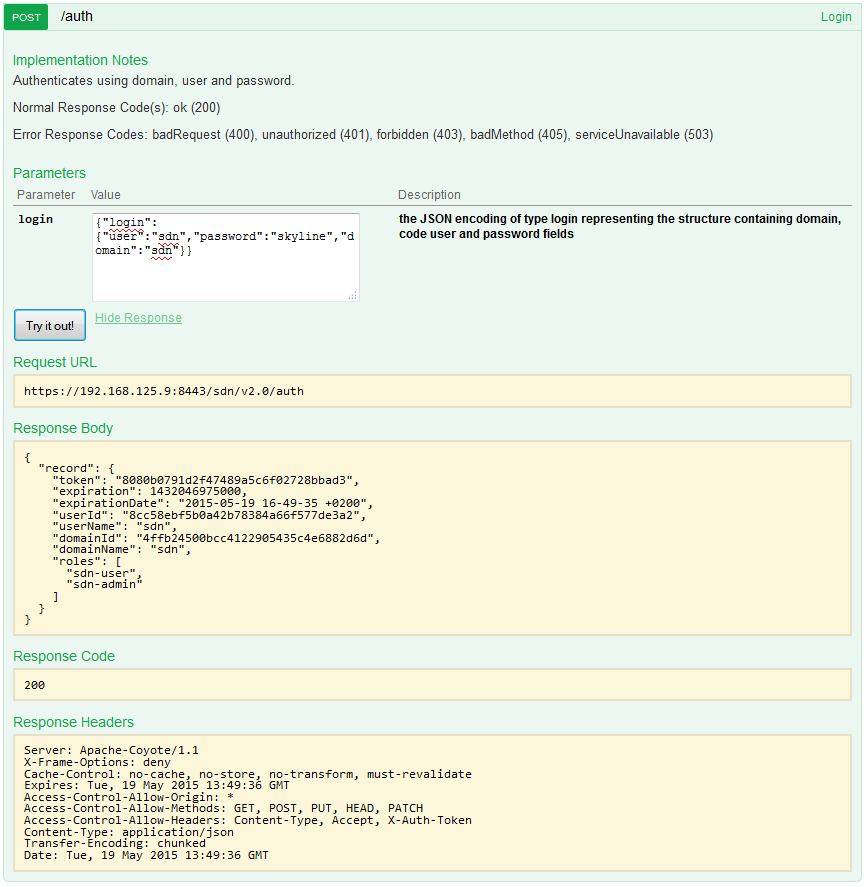
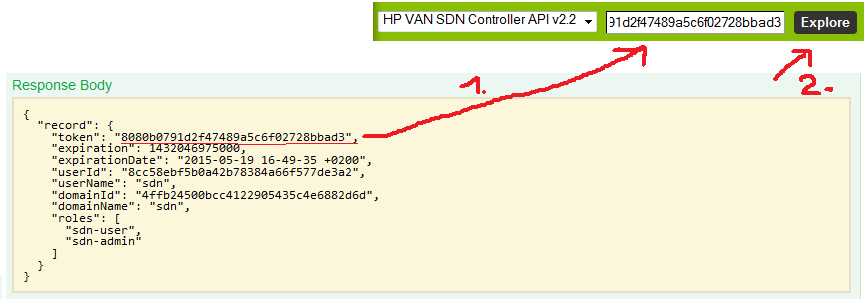
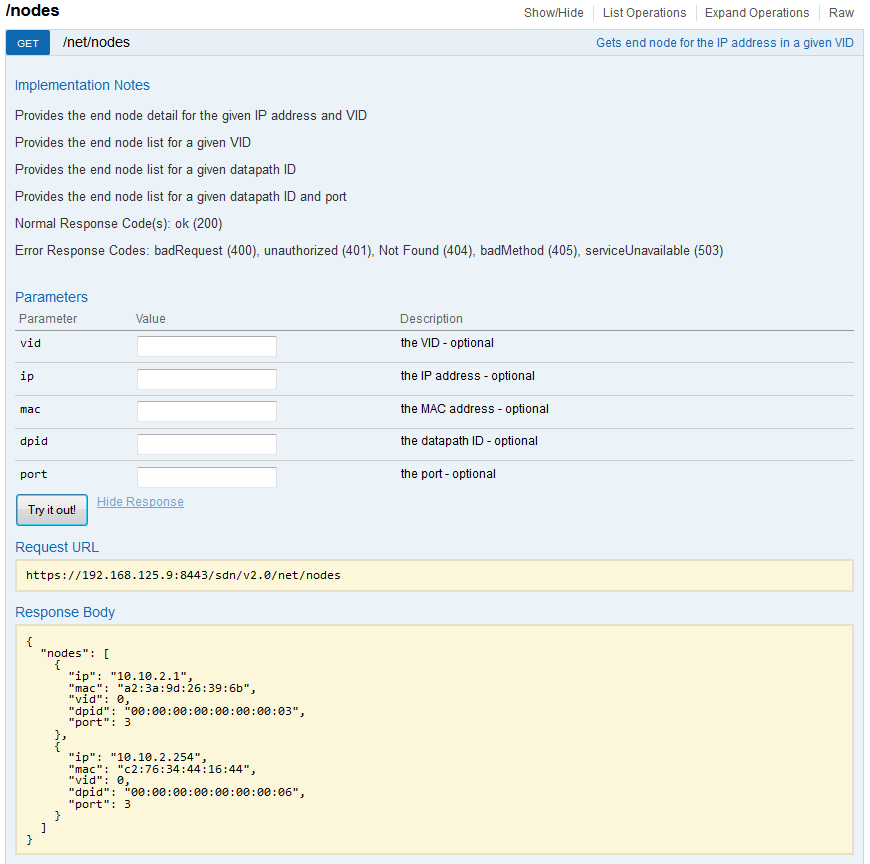
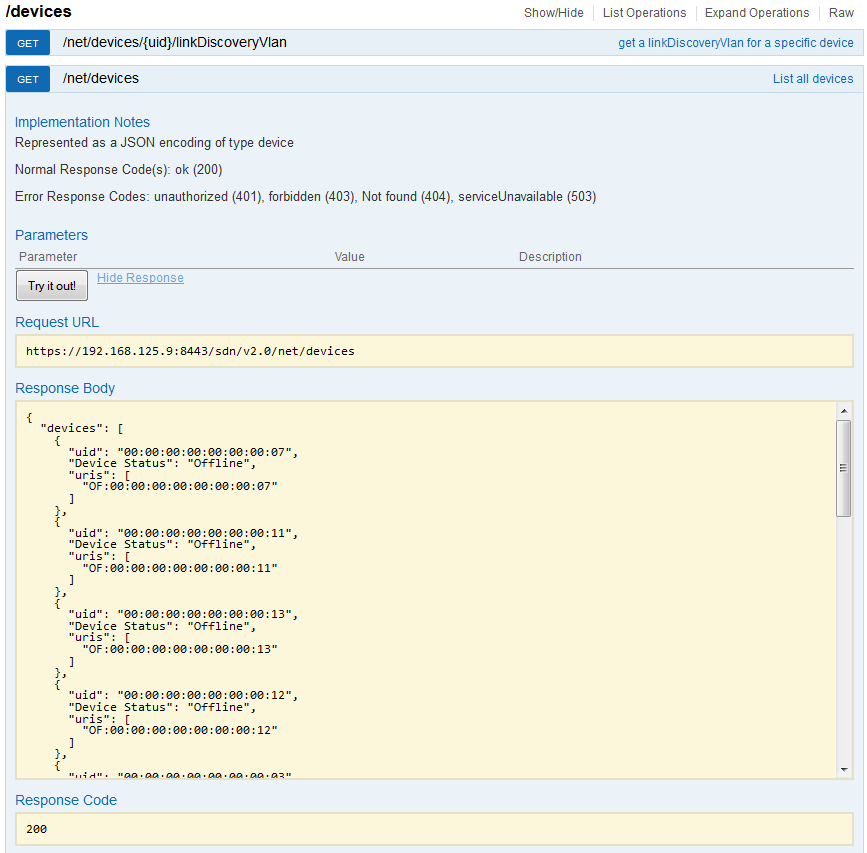
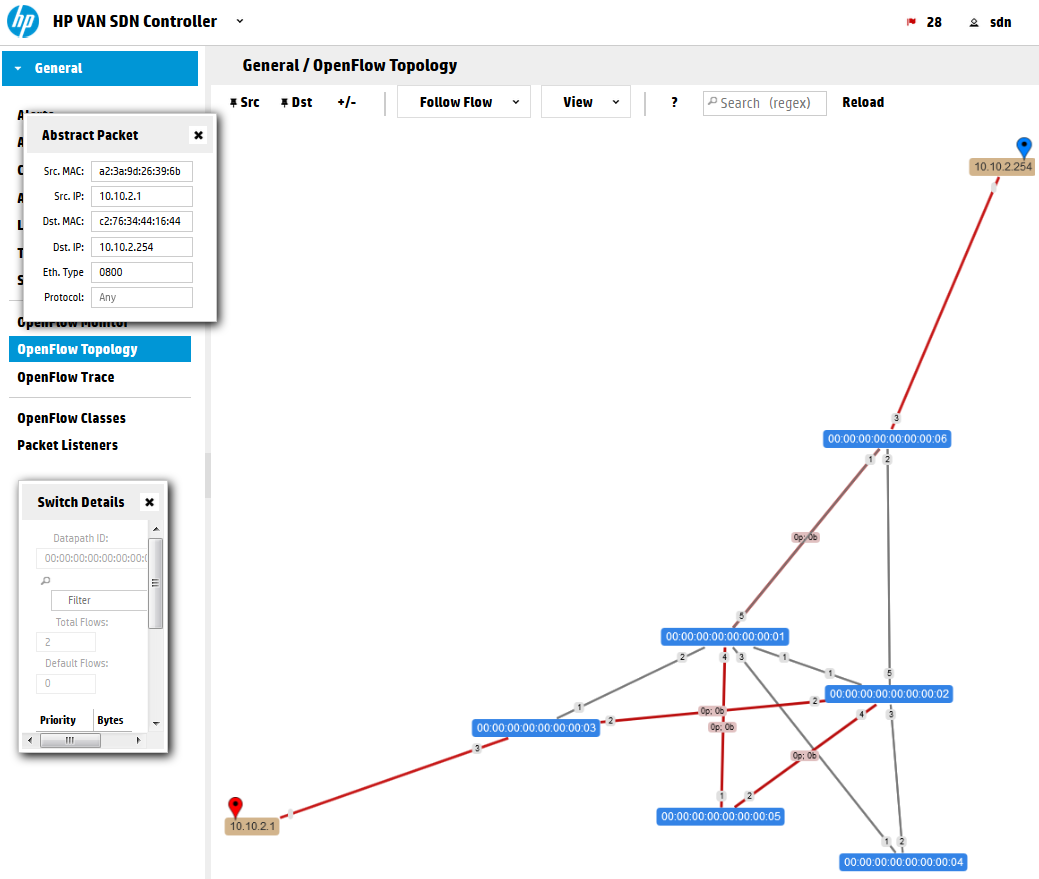
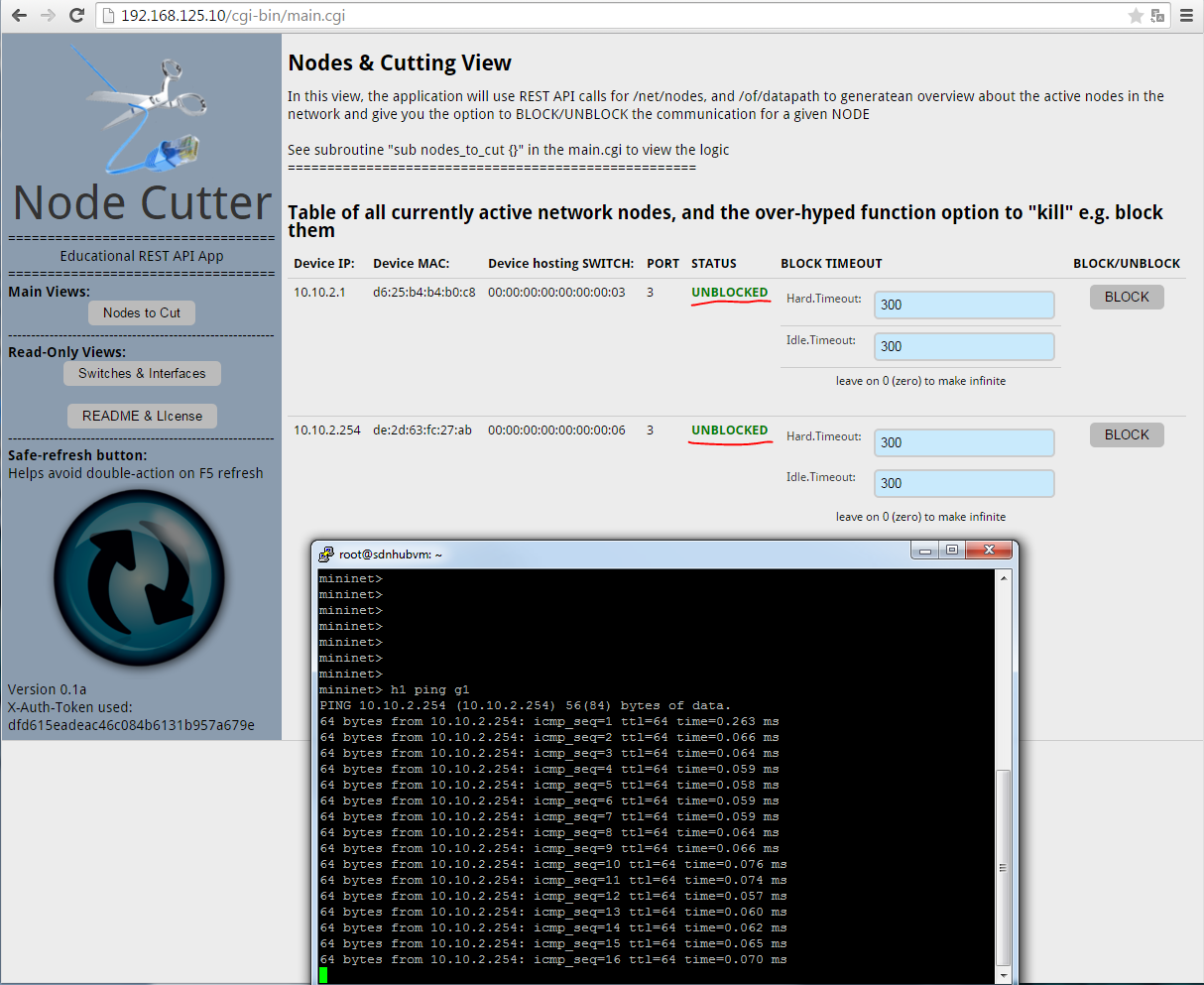
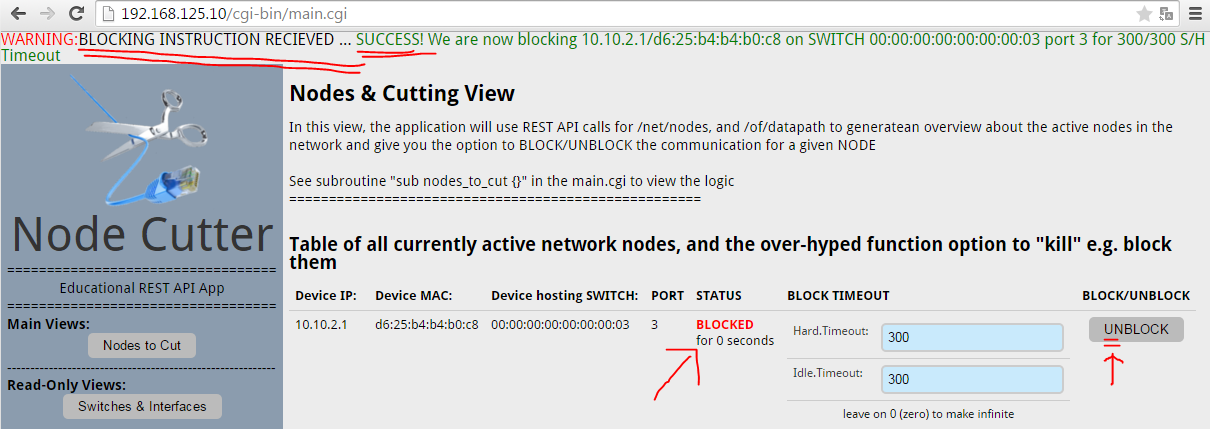
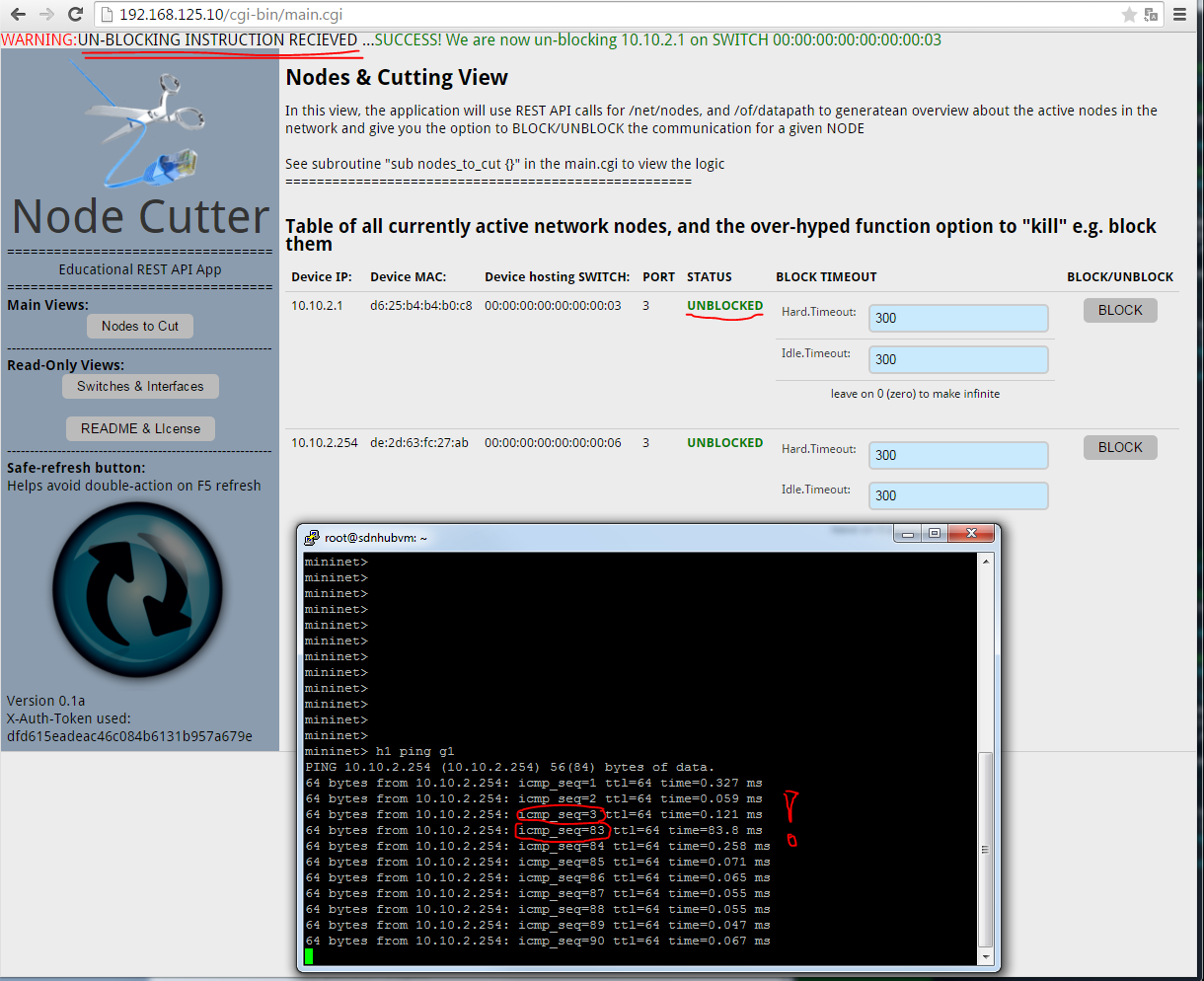
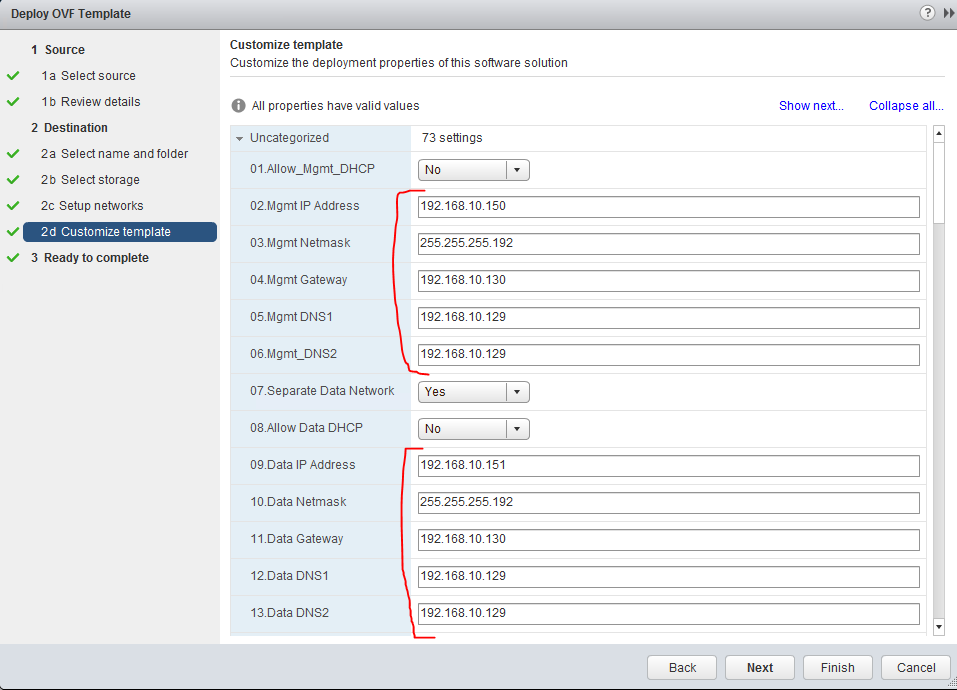
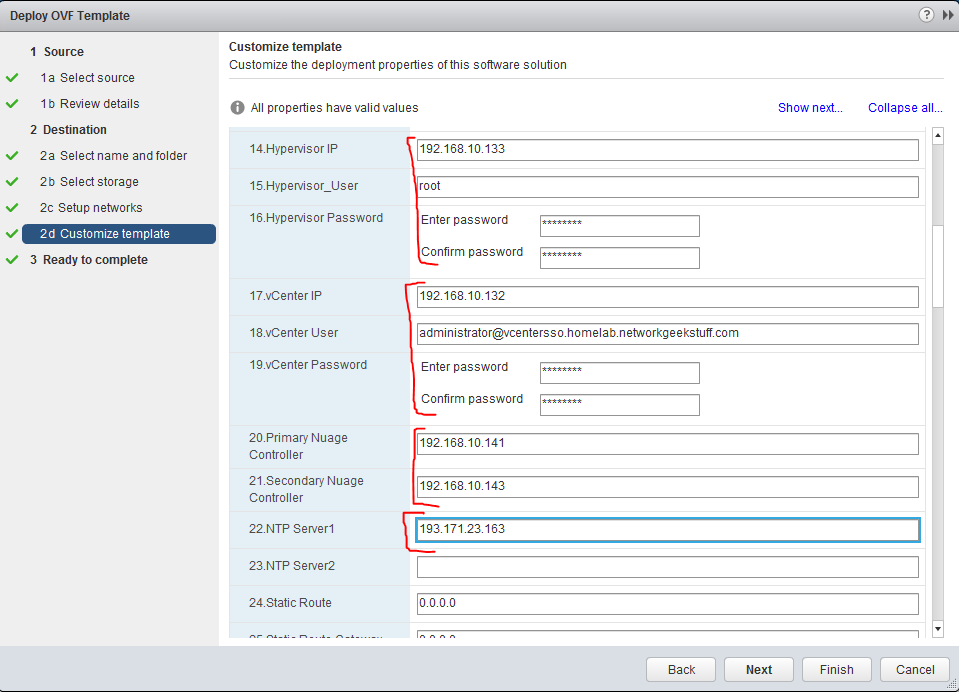
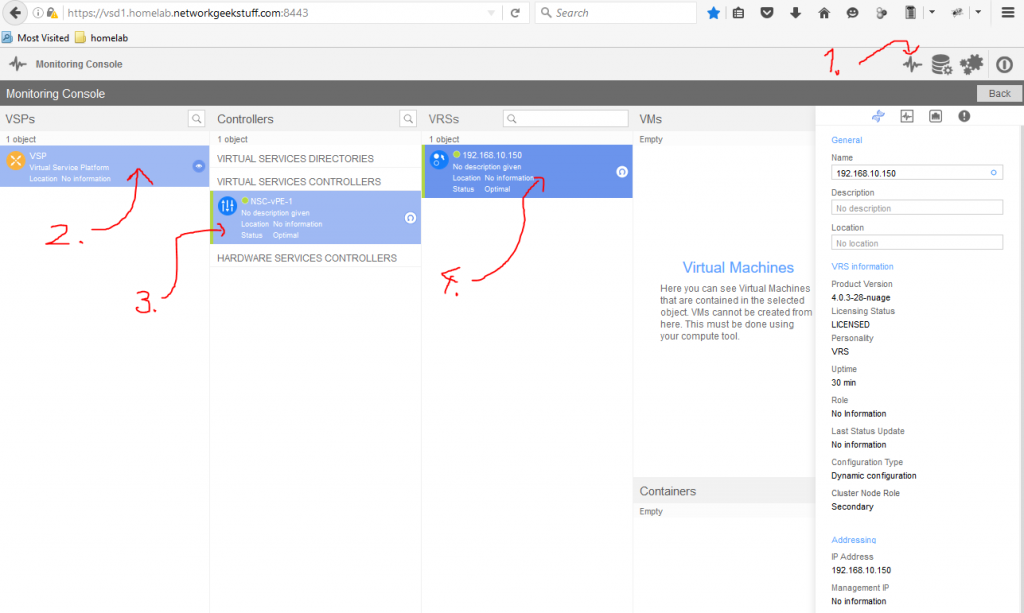
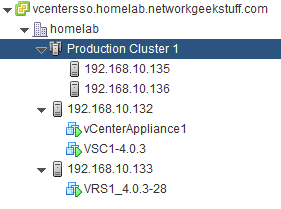
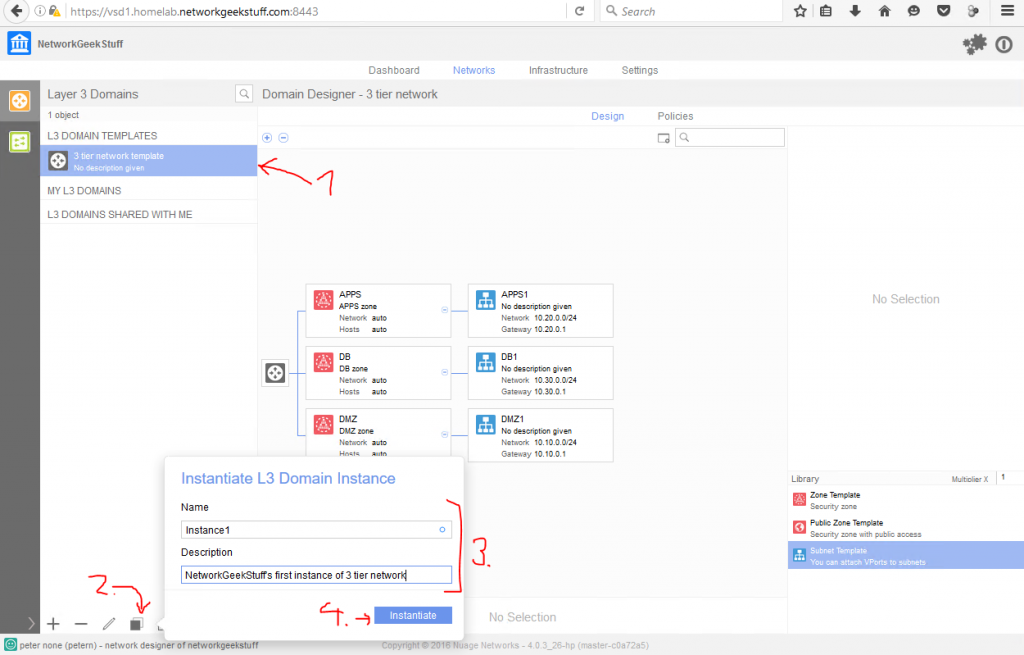
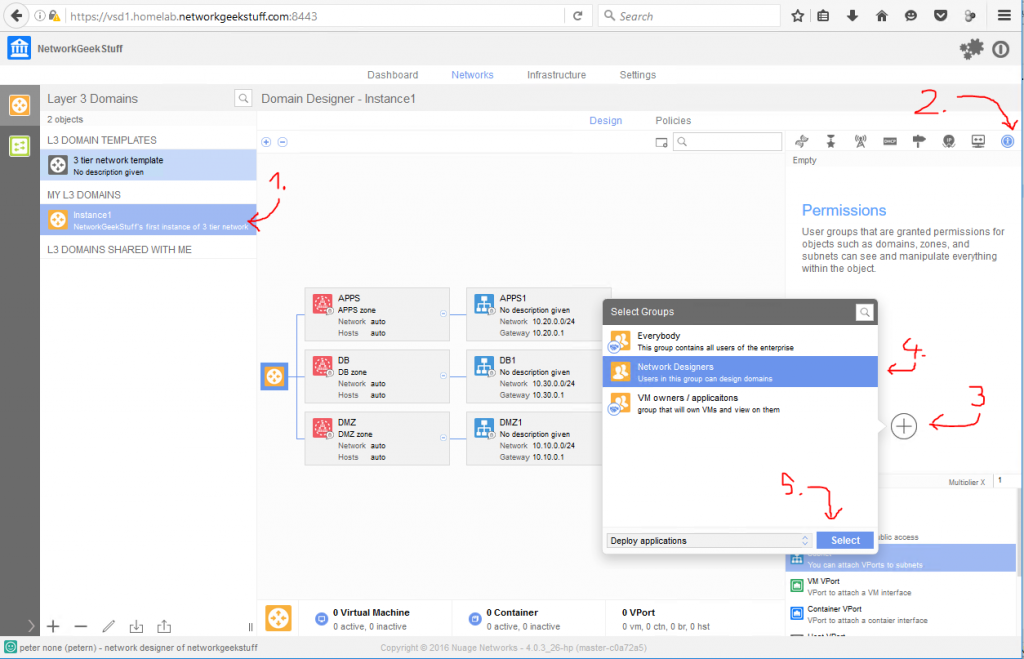
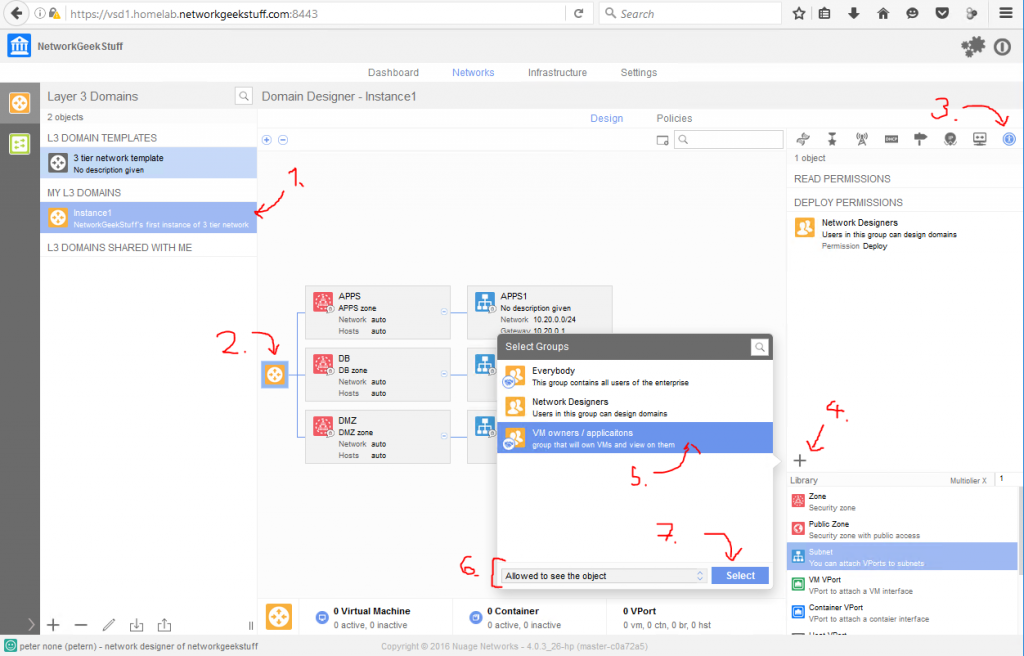
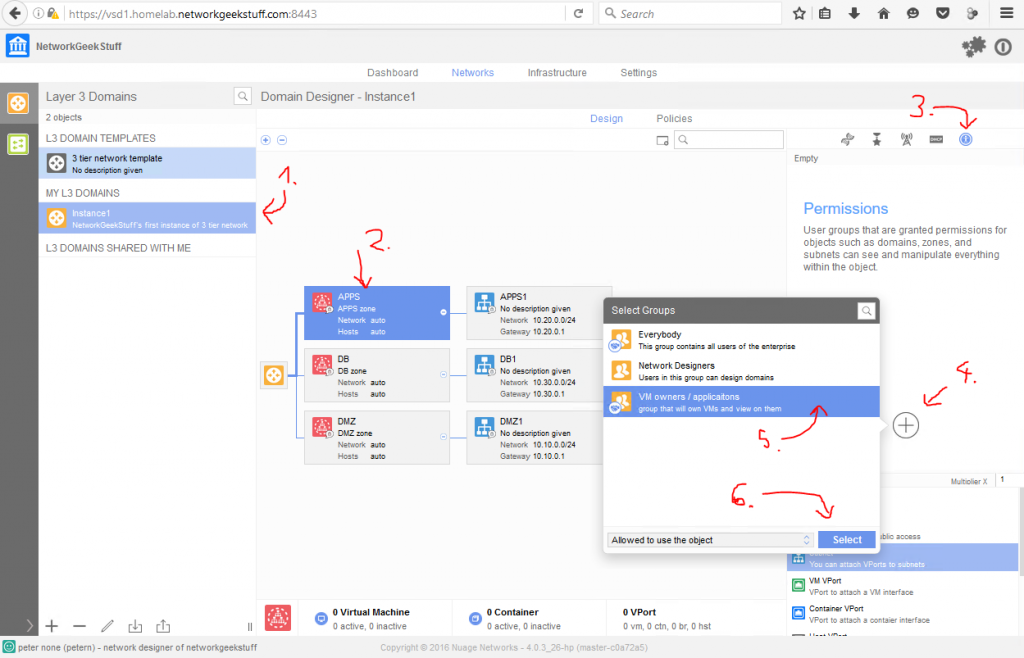
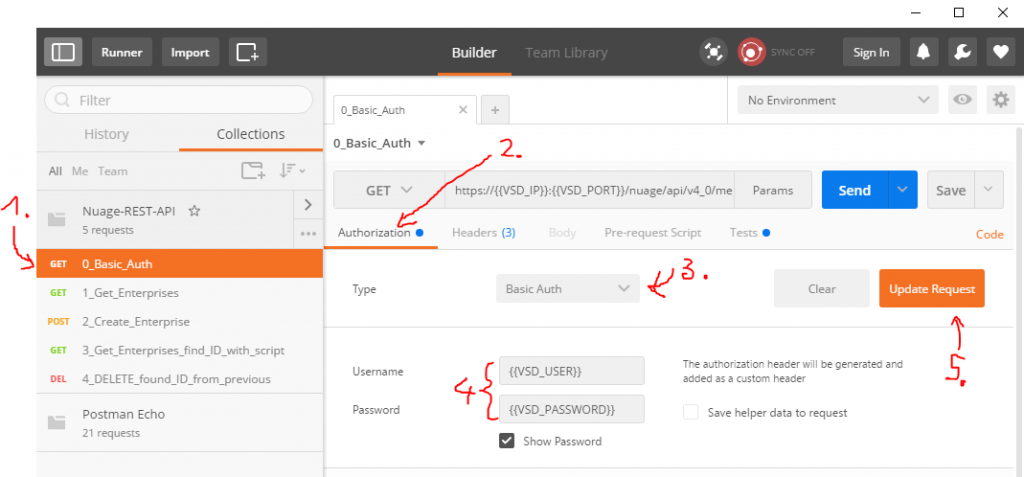
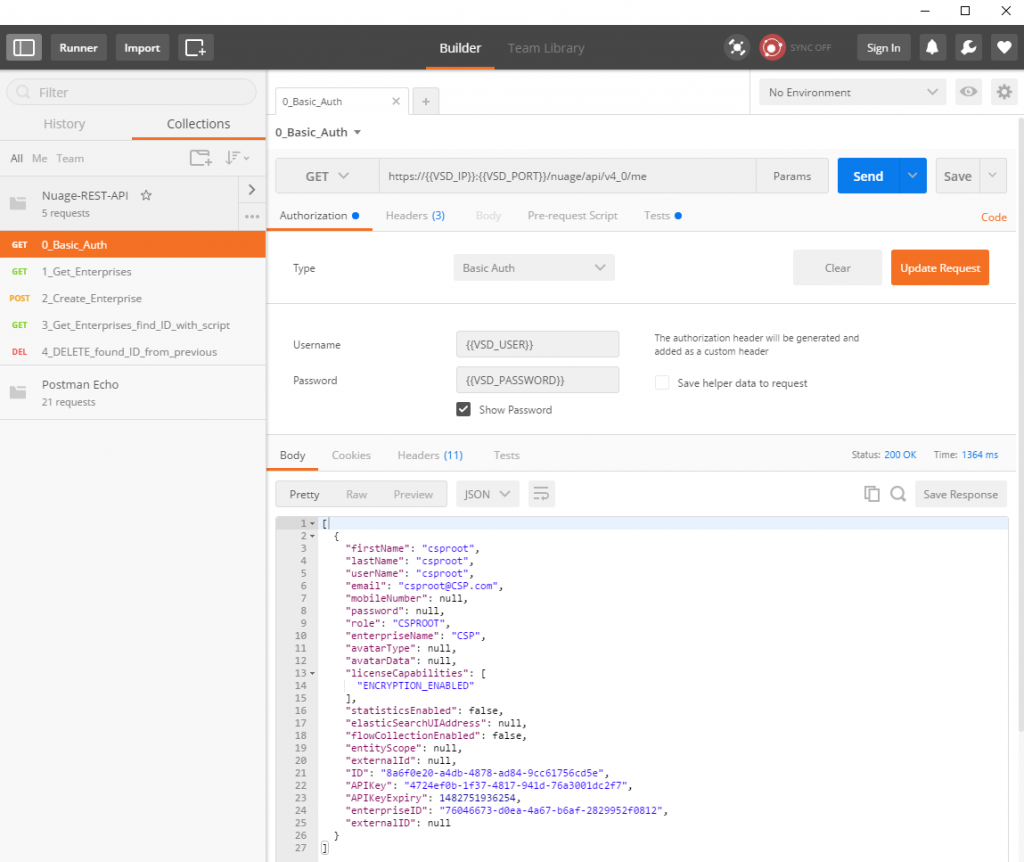
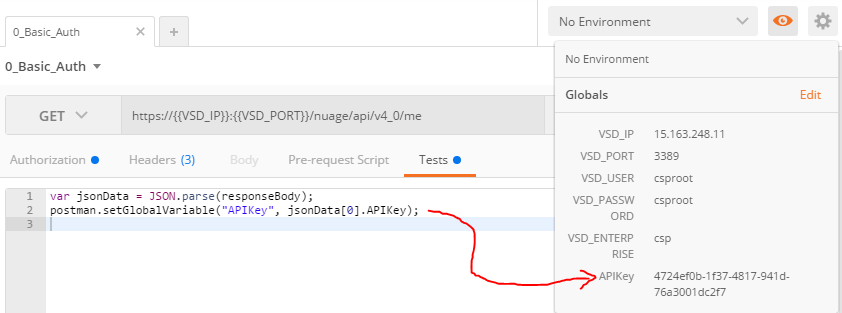
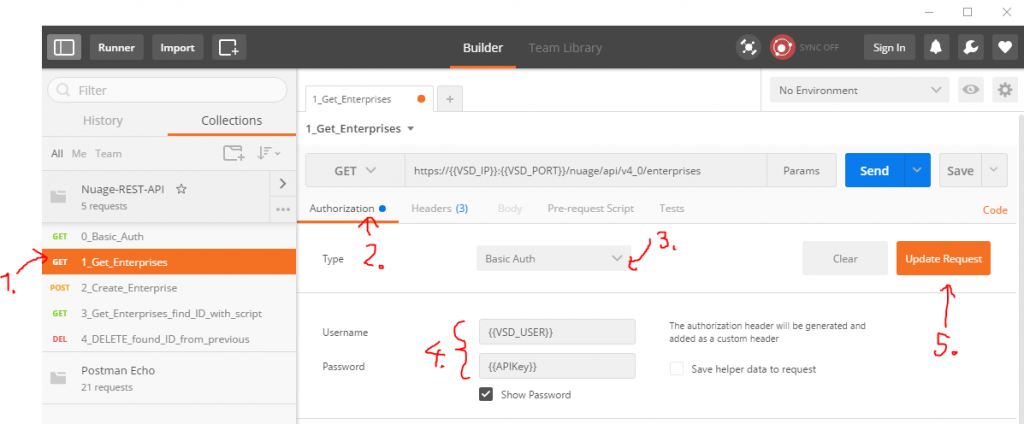
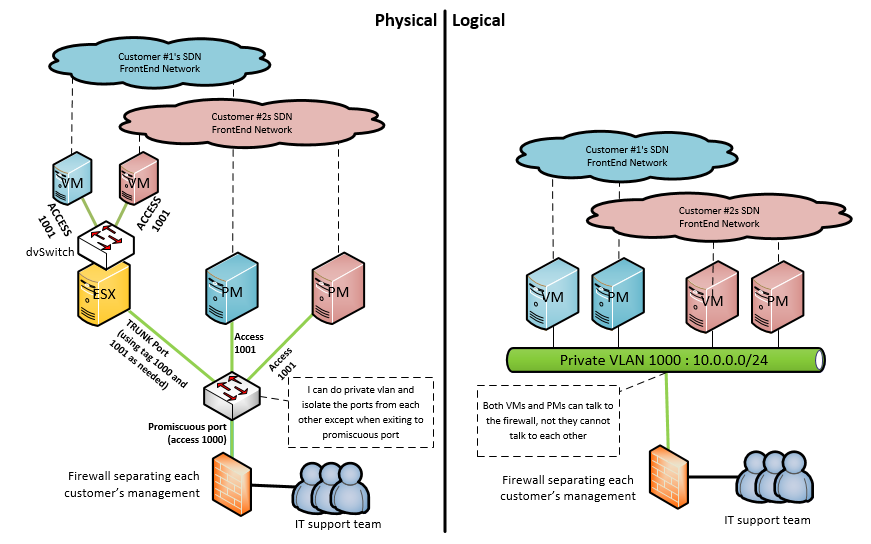
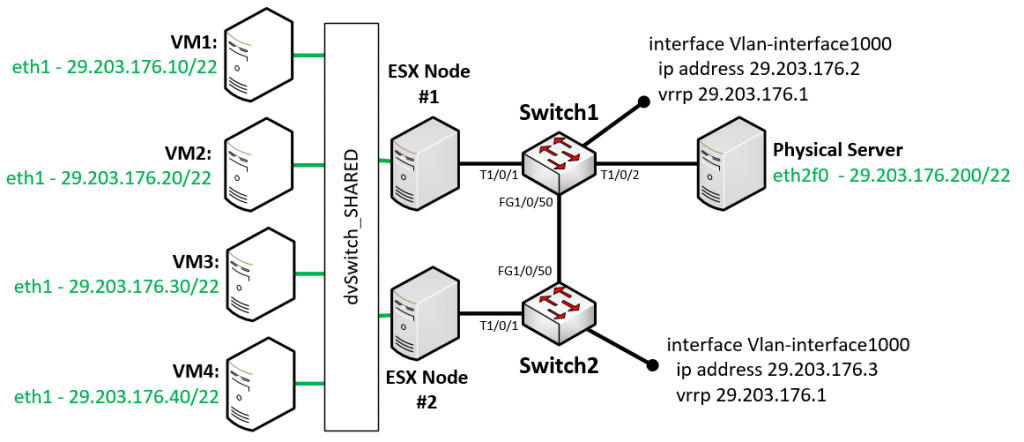
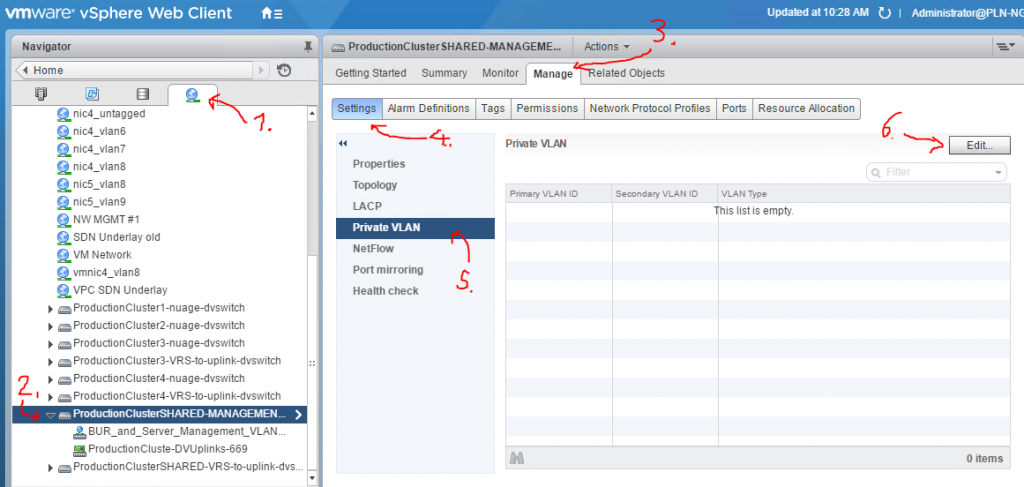
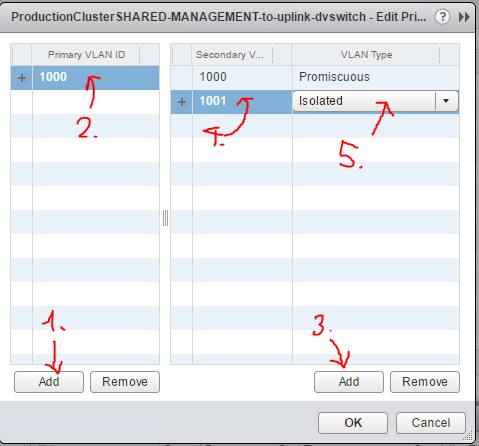
For best article visual quality, open Introduction and LAB tutorial of HP Helion Community Edition, the OpenStack based “cloud” system that can give you a personal cloud! directly at NetworkGeekStuff.
Hewlett-Packard (HP) is a long enterprise supporter of cloud technologies and early this year, they released publicly HP Helion Community Edition (CE). HP Helion is HP’s OpenStack based cloud system with which HP plans to provide value added services (both in sense of software and service) with the upcoming release of HP Helion Enterprise edition later this year. In this article, I plan to introduce you to the HP Helion CE, quickly guide you through the installation, basic operations and in the end get you a quick view on the OpenStack architecture in general.
HP and “clouds”
![HPCloud]()
For a long time HP has been providing cloud solution based on their internal Cloud Service Automation or “CSA” system to enterprise grade customers as part of their portfolio. I had access to several projects using this environment and although I still have mixed feelings about their effectiveness, they were a step in the right direction as classical (now called “legacy”) data-centers are loosing popularity to cloud and other automated systems. The newest approach HP has taken however appears to be even better than anything in their current enterprise portfolio and the biggest honeypot is integration of OpenStack to a HP system called “HP Helion”.
For those who do not know OpenStack, it is an open source project that is uniting right now most of the datacenter automation efforts for control and provisioning of networking/storage/computing (means servers) under one GUI covered logic. My more elemental explanation, which I am giving to people, is that OpenStack is trying to put together all the independent automation work that both bigger and smaller companies providing virtual servers have been doing internally and standardizing it. To get some quick and practical touch of OpenStack, I encourage you to either install one of the prepared distros like Cloudbuntu (ubuntu with openstack integrated) or go to openstack.org and try to integrate openstack natively to the linux/unix of your choice. Just note that OpenStack is a provisioning system designed to run on multiple servers, so expect that if you want to run in only on your one PC, you will have to play with wmvare or virtualbox to give openstack at least minimal architecture (with 4 servers) it needs.
HP Helion is a integration layer of added value software, streamlined installation and also optional enterprise support license on top of OpenStack cloud system. Technically HP wants to give out their own “flavour” of OpenStack and sell support service. Also HPs internal enterprise organizations that are providing both dedicated or leveraged cloud services to enterprise customers are now working on adopting HP Helion with their older Cloud Service Automation 4.0 (CSA 4.0) because OpenStack provides many things (like network gui) that CSA didn’t had. To get a feeling about HP Helion operations you can do two independent things depending on your free time.
Option 1: go to hpcloud.com and get a 90 day trial of their cloud services. This is similar to the amazon cloud service in that you can very quickly get a virtual server from HP, get a public IP for it and just play. The big advantage here is the gui that enables you not only to get a server, but to actually get a full network topology around it.
Option 2: Download HP Helion community edition and install it in a lab. This is the option we will now pursue for the rest of this article. The community edition exists because OpenStack is an open source software so HP doesn’t own it and has to release a open source version of any derivative work they want to do.
Installing HP Helion community edition
First, the prerequisites for HP Helion are officialy:
- At least 16 GB of RAM
- At least 200 GB of available disk space (although really the install will take around 80GB, so if you have around 140GB free to have something free also for VMs, you are OK)
- Virtualization support enabled in the BIOS
NOTE: I originally didn’t had 16GB of RAM, so I somehow managed to find most virtual machines definitions of RAM and lower it, but the system is then using swap area like crazy and essentially rendered the installation unusable. If you really try to push it to run on less than 16GB of RAM it is possible, but at least try to use an SSD disk for it as otherwise you will loose your nerves here.
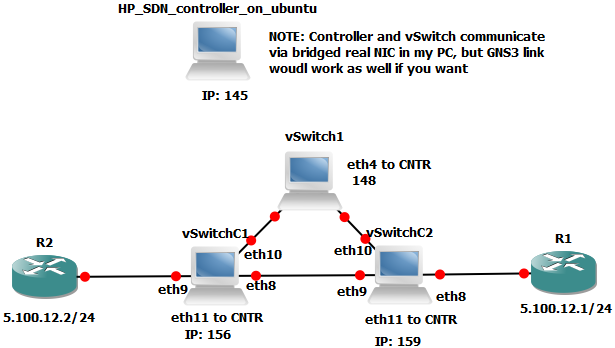
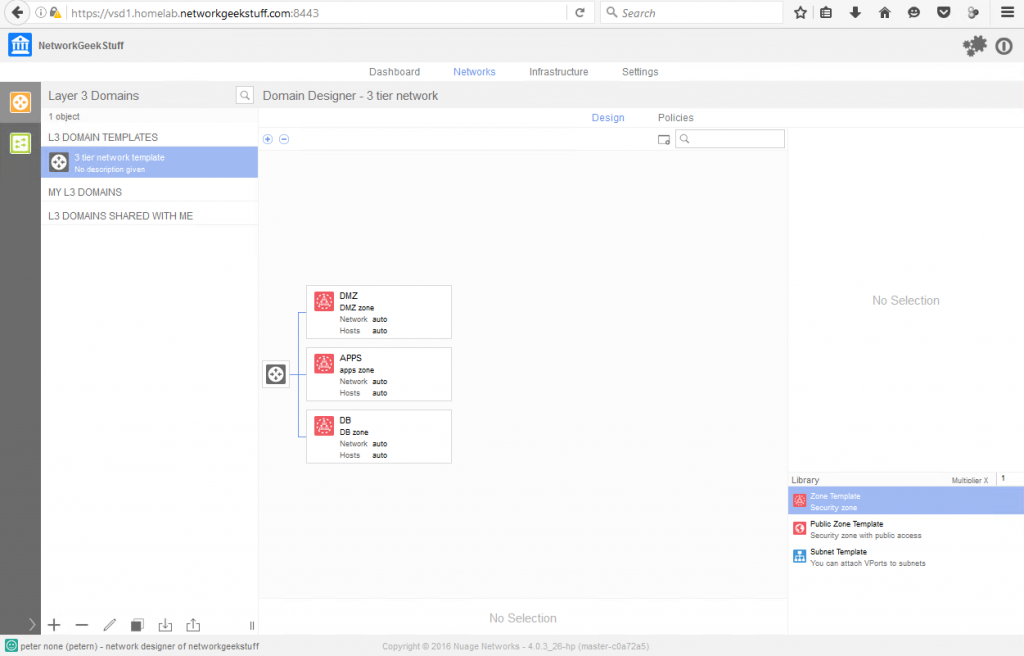
Target architecture of virtual-in-virtual HP Helion CE
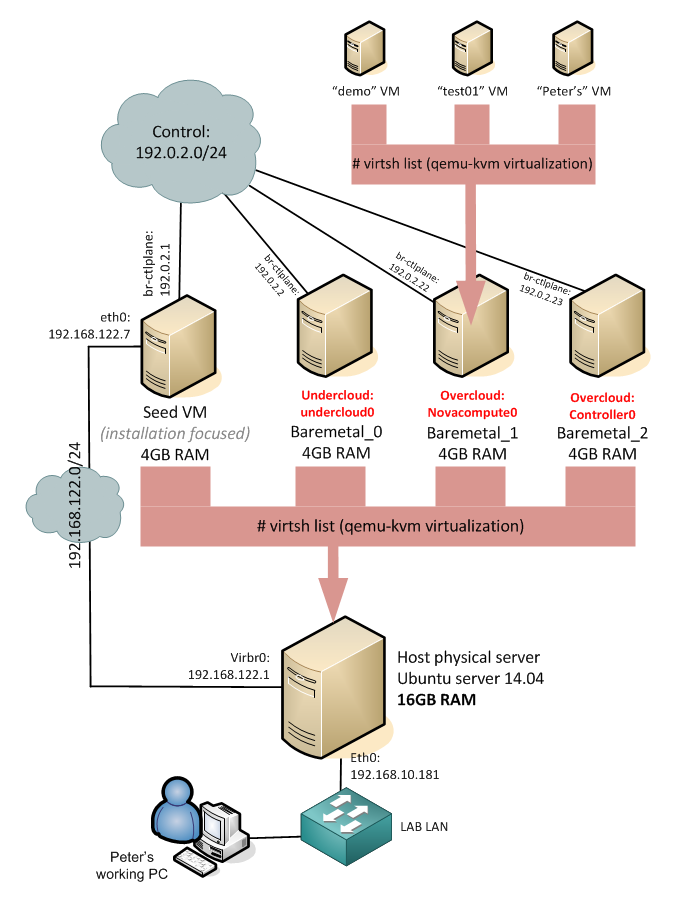
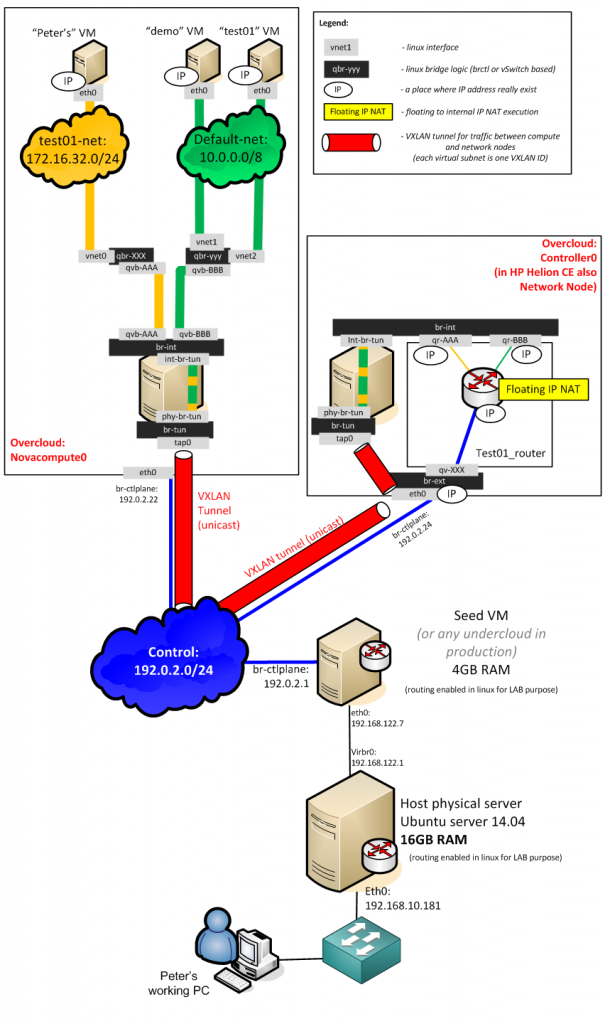
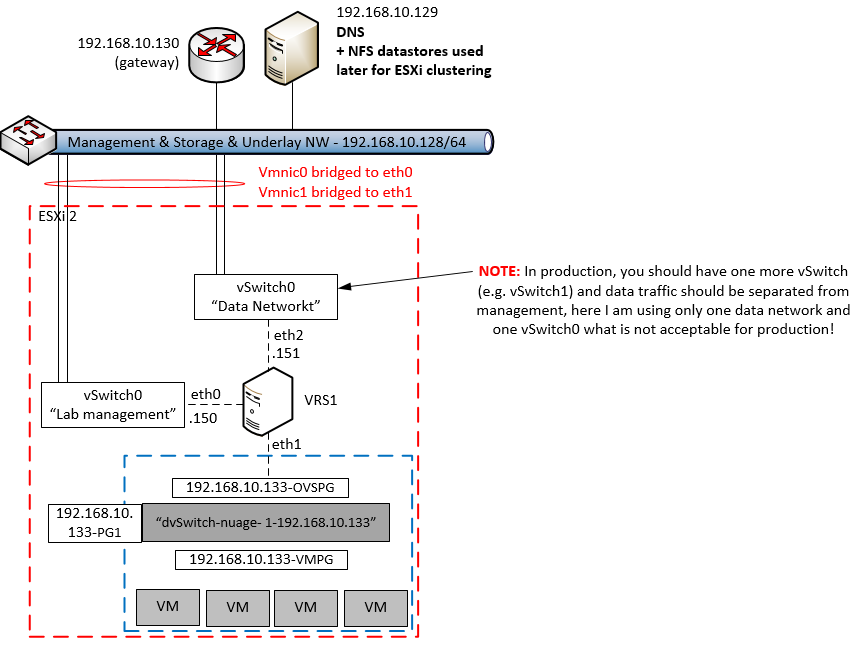
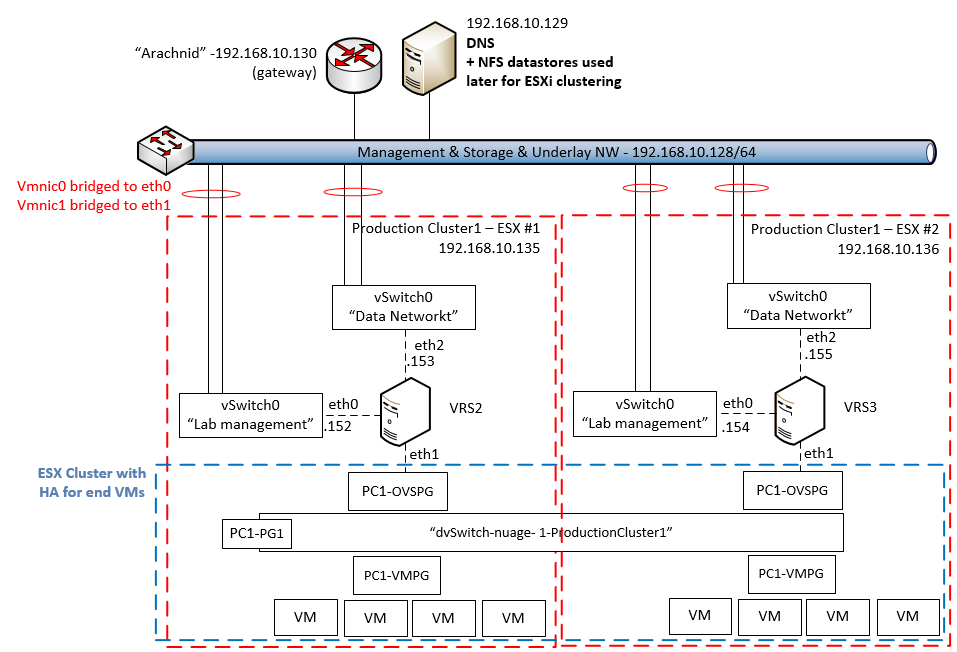
Before we go to the actual steps, let me show you the architecture that we will create in this LAB. The HP Helion is using the TripleO installation, which is part of OpenStack project as an installation path which deploys everything from pre-created system images. HP modified this approach to give you a quick to deploy example topology, where the classical OpenStack components (which should normally run natively on baremetal servers) are also virtualized. This means that your single machine with 16GB will be running a first layer of virtualization and virtualize the OpenStack/HP Helion server nodes. And thse internal nodes will then run the end-user virtual machines. So we have a dual layer virtualization. Maybe to help you understand this (including the networks that will be created between them) I have put together this picture of the final architecture.
![HP Helion GE - June 2014 installation using TripleO and deploying defalt virtual-in-virtual]()
HP Helion GE – June 2014 installation using TripleO and deploying default virtual-in-virtual
On the picture above, all servers with the exception of the “Host physical server” and my working PC are virtual machines. HP Helion deploys 4x virtual machine (4GB each) and then these machines will run smaller virtual systems inside. The “demo”, “test01″ and “Peter’s” virtual machines we will create (including advanced networking) in the steps below.
Step 1: Install Ubuntu 14.04 as base operating system
Step 2: install software packages needed
apt-get install -y libvirt-bin openvswitch-switch python-libvirt \
qemu-system-x86 qemu-kvm openssh-server
after the libvirt is installed, you have to restart its service
/etc/init.d/libvirt-bin restart
also generate a public/private key pair for root with. Do not create a passphrase for the keys, just hit enter when asked for new password
ssh-keygen -t rsa
Step 3: Unpack the installation hp_helion_openstack_community.tar.gz of HP Helion
You have downloaded the hp_helion_openstack_community.tar.gz from here. Now you need to extract it with tar command like this
tar zxvf hp_helion_openstack_community.tar.gz
Step 4: Start the seed VM
The Helion uses a tripleo installation system,
HP_VM_MODE=y
bash -x ~root/tripleo/tripleo-incubator/scripts/hp_ced_start_seed.sh
The script will run for at minimum for a few minutes. Finishing with message similar to this:
HP - completed - Sun Jun 8 16:48:04 UTC 2014
At the end, you should see a “seed” virtual machine created in your host system, feel free to check the virsh list command
root@HPHelion1:~# virsh list
Id Name State
----------------------------------------------------
0 seed running
SCRIPT POSSIBLE FAILURE NOTE #1: The installation has run on my PC but ended with error like this:
error: Failed to start domain seed
error: unsupported configuration: SATA is not supported with this QEMU binary
I had to edit the virsh “seed machine” template in ~/tripleo/tripleo-incubator/templates/vm.xml
Just find this line:
<target dev='sda' bus='sata'/>
and change it to “ide”
<target dev='sda' bus='ide'/>
SCRIPT POSSIBLE FAILURE NOTE #2: The initial “seed” virtual machine will try to use 4096MB, if you want to try smaller RAM (for example I had to change it to 2048MB because my host server didn’t had enough RAM), you can open the ~/tripleo/tripleo-incubator/scripts/hp_ced_start_seed.sh, find a line there that contains “MEMORY=${NODE_MEM:-4096}” and change the 4096 there to the RAM value you need. However, prepare your HDD for quite intensive work as the virtual seed will extensively use the swap area.
Step 5: Start overcloud/undercloud
What Helion has don in Step 4 is that it created a virtual network and a few virtual bridge interfaces in your linux host. If you look at ifconfig, you will notice new interfaces and most importantly this one:
root@HPHelion1:~# ifconfig virbr0
virbr0 Link encap:Ethernet HWaddr fe:54:00:6a:86:a8
inet addr:192.168.122.1 Bcast:192.168.122.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:451 errors:0 dropped:0 overruns:0 frame:0
TX packets:392 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:49375 (49.3 KB) TX bytes:61062 (61.0 KB)So we have a new network 192.168.122.0/24 and also, if you look at routing table, there is new static route for 192.0.2.0/24 in the routing table with next-hop to 192.168.122.103 (which is the seed VM).
root@HPHelion1:~# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.10.130 0.0.0.0 UG 0 0 0 eth0
192.0.2.0 192.168.122.103 255.255.255.0 UG 0 0 0 virbr0
192.168.10.128 0.0.0.0 255.255.255.192 U 0 0 0 eth0
192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0
Now, let’s continue at connect to the seed VM with ssh 192.0.2.1 (execute as root) and you will end on the seed VM like this:
root@HPHelion:~# ssh 192.0.2.1
<ommitted>
root@hLinux:~#
Now what is needed is to run a similar script to create new virtual machines inside the virtual seed machine, lets call it “hLinux” for lack of a better word now.
bash -x ~root/tripleo/tripleo-incubator/scripts/hp_ced_installer.sh
I do not want to copy&paste everything from this installation, but note that on my system, this script took 2 hours to complete, mostly I believe because of the SATA drive (classical HDD, not SSD) which hosted 4x virtual machines that all wanted to use their virtual drives. So this slowed the system significantly. Interesting points to notice in the installation are these different identifications of API access and initial virtual machines definitions:
THIS INSTALL LOG BELOW IS JUST “FYI”,
IF YOU HAD NO PROBLEMS/ERRORS IN YOUR INSTALL, FEEL FREE TO SKIP TO STEP 6.
+-------------+----------------------------------+
| Property | Value |
+-------------+----------------------------------+
| adminurl | http://192.0.2.1:35357/v2.0 |
| id | de7a8875c4e34d388338d2d82df2193f |
| internalurl | http://192.0.2.1:5000/v2.0 |
| publicurl | http://192.0.2.1:5000/v2.0 |
| region | regionOne |
| service_id | b7a68ce3dc094ae795dc5fdc6799cc0c |
+-------------+----------------------------------+
Service identity created
+ setup-endpoints 192.0.2.1 --glance-password unset --heat-password unset --neutron-password unset --nova-password unset
No user with a name or ID of 'heat' exists.
+-------------+----------------------------------------+
| Property | Value |
+-------------+----------------------------------------+
| adminurl | http://192.0.2.1:8004/v1/%(tenant_id)s |
| id | 26d2083e2aa14af09e118c1cf2b5425b |
| internalurl | http://192.0.2.1:8004/v1/%(tenant_id)s |
| publicurl | http://192.0.2.1:8004/v1/%(tenant_id)s |
| region | regionOne |
| service_id | 5046569b46ca4adba810ee059ba0458f |
+-------------+----------------------------------------+
Service orchestration created
No user with a name or ID of 'neutron' exists.
+-------------+----------------------------------+
| Property | Value |
+-------------+----------------------------------+
| adminurl | http://192.0.2.1:9696/ |
| id | 3e2019589728491ca11ce4b3ba084b00 |
| internalurl | http://192.0.2.1:9696/ |
| publicurl | http://192.0.2.1:9696/ |
| region | regionOne |
| service_id | 24afe3d3797f4ed9a196160bde6bdf5b |
+-------------+----------------------------------+
Service network created
No user with a name or ID of 'glance' exists.
+-------------+----------------------------------+
| Property | Value |
+-------------+----------------------------------+
| adminurl | http://192.0.2.1:9292/ |
| id | 7bca793c84504ee3bd8a77846aa604f1 |
| internalurl | http://192.0.2.1:9292/ |
| publicurl | http://192.0.2.1:9292/ |
| region | regionOne |
| service_id | 2ff2d413b5f04ca7aa6c8fd2cec65971 |
+-------------+----------------------------------+
Service image created
No user with a name or ID of 'ec2' exists.
+-------------+--------------------------------------+
| Property | Value |
+-------------+--------------------------------------+
| adminurl | http://192.0.2.1:8773/services/Admin |
| id | 6bf46d7e33294b589f575ffc10fa6592 |
| internalurl | http://192.0.2.1:8773/services/Cloud |
| publicurl | http://192.0.2.1:8773/services/Cloud |
| region | regionOne |
| service_id | 2f08c13c51664c7ab48329c6723af6f6 |
+-------------+--------------------------------------+
Service ec2 created
No user with a name or ID of 'nova' exists.
+-------------+----------------------------------------+
| Property | Value |
+-------------+----------------------------------------+
| adminurl | http://192.0.2.1:8774/v2/$(tenant_id)s |
| id | a9d0eaaa823b4fdbbc14daa7b4717dfc |
| internalurl | http://192.0.2.1:8774/v2/$(tenant_id)s |
| publicurl | http://192.0.2.1:8774/v2/$(tenant_id)s |
| region | regionOne |
| service_id | 37cacb6157d94f4cac62be090702e552 |
+-------------+----------------------------------------+
Service compute created
+-------------+----------------------------------+
| Property | Value |
+-------------+----------------------------------+
| adminurl | http://192.0.2.1:8774/v3 |
| id | 84de8d8141494b9b99c4b109f461247c |
| internalurl | http://192.0.2.1:8774/v3 |
| publicurl | http://192.0.2.1:8774/v3 |
| region | regionOne |
| service_id | d02b76ad1ebb4ea0a7a02850b526b0dc |
+-------------+----------------------------------+
Service computev3 created
+ keystone role-create --name heat_stack_user
+----------+----------------------------------+
| Property | Value |
+----------+----------------------------------+
| id | d1aeb2393fc8455ca8762494be0c5e7c |
| name | heat_stack_user |
+----------+----------------------------------+
+ keystone role-create --name=swiftoperator
+----------+----------------------------------+
| Property | Value |
+----------+----------------------------------+
| id | 57d9e615646b418f8253304181d7c7b8 |
| name | swiftoperator |
+----------+----------------------------------+
+ keystone role-create --name=ResellerAdmin
+----------+----------------------------------+
| Property | Value |
+----------+----------------------------------+
| id | dafea872903e49a58ef14b8e3b3593aa |
| name | ResellerAdmin |
+----------+----------------------------------+
++ setup-neutron '' '' 10.0.0.0/8 '' '' '' 192.0.2.45 192.0.2.64 192.0.2.0/24
Created a new router:
+-----------------------+--------------------------------------+
| Field | Value |
+-----------------------+--------------------------------------+
| admin_state_up | True |
| external_gateway_info | |
| id | ba1476fc-2922-44ed-ba81-af5d3e156865 |
| name | default-router |
| status | ACTIVE |
| tenant_id | 73c6d757dac243a0a9b9143b5f6be2e3 |
+-----------------------+--------------------------------------+
Added interface 90dd4dae-2f16-45fd-8b68-4fa54985dde0 to router default-router.
Created a new network:
+---------------------------+--------------------------------------+
| Field | Value |
+---------------------------+--------------------------------------+
| admin_state_up | True |
| id | c0edfb5c-fa09-49e6-92fe-014e60c6d095 |
| name | ext-net |
| provider:network_type | vxlan |
| provider:physical_network | |
| provider:segmentation_id | 1002 |
| router:external | True |
| shared | False |
| status | ACTIVE |
| subnets | |
| tenant_id | 73c6d757dac243a0a9b9143b5f6be2e3 |
+---------------------------+--------------------------------------+
Set gateway for router default-router
++ os-adduser -p a304b9d3c3d9def5c4978ed7f0ca3e622a5d6f1c demo demo@example.com
Created user demo with password 'a304b9d3c3d9def5c4978ed7f0ca3e622a5d6f1c'
++ nova flavor-delete m1.tiny
++ nova flavor-create m1.tiny 1 512 2 1
+----+---------+-----------+------+-----------+------+-------+-------------+-----------+
| ID | Name | Memory_MB | Disk | Ephemeral | Swap | VCPUs | RXTX_Factor | Is_Public |
+----+---------+-----------+------+-----------+------+-------+-------------+-----------+
| 1 | m1.tiny | 512 | 2 | 0 | | 1 | 1.0 | True |
+----+---------+-----------+------+-----------+------+-------+-------------+-----------+
At the end, you should see something similar to this:
HP - completed - Sun Jun 8 16:48:04 UTC 2014
Step 6: Verification of your install
There are verification steps that you can do inside both the seed VM (hLinux) and also your server OS.
Lets start with the test provided by HP Helion scripts which will list the overcloud VMs and undercloud VMs, which are the infrastructure VMs running the Compute and Controller nodes.
root@hLinux:~# source ~root/tripleo/tripleo-undercloud-passwords
root@hLinux:~# TE_DATAFILE=~/tripleo/testenv.json
root@hLinux:~# source ~root/tripleo/tripleo-incubator/undercloudrc
root@hLinux:~# nova list
+--------------------------------------+-------------------------------------+--------+------------+-------------+---------------------+
| ID | Name | Status | Task State | Power State | Networks |
+--------------------------------------+-------------------------------------+--------+------------+-------------+---------------------+
| 1d51fdd8-468c-4988-b717-74a47e1f6914 | overcloud-NovaCompute0-4r2q45kefrrm | ACTIVE | - | Running | ctlplane=192.0.2.22 |
| 30709eb7-511f-4bea-bcfa-58b7ee01c9cf | overcloud-controller0-6yxubmu4x2eg | ACTIVE | - | Running | ctlplane=192.0.2.23 |
+--------------------------------------+-------------------------------------+--------+------------+-------------+---------------------+
Second, this series will show you the overcloud VMs, which are the instances running as if end user VMs. Based on this list, you will find the defaulty provided example “demo” Instance and you can also ping the “demo” VM on its 192.x.x.x interface:
root@hLinux:~# source ~root/tripleo/tripleo-overcloud-passwords
root@hLinux:~# TE_DATAFILE=~/tripleo/testenv.json
root@hLinux:~# source ~root/tripleo/tripleo-incubator/overcloudrc-user
root@hLinux:~# nova list
+--------------------------------------+------+--------+------------+-------------+----------------------------------+
| ID | Name | Status | Task State | Power State | Networks |
+--------------------------------------+------+--------+------------+-------------+----------------------------------+
| 9e40b5b0-c70d-4797-9b95-c3d3e39c897e | demo | ACTIVE | - | Running | default-net=10.0.0.2, 192.0.2.46 |
+--------------------------------------+------+--------+------------+-------------+----------------------------------+
-
root@hLinux:~# ping 192.0.2.46
PING 192.0.2.46 (192.0.2.46) 56(84) bytes of data.
64 bytes from 192.0.2.46: icmp_seq=1 ttl=63 time=12.2 ms
64 bytes from 192.0.2.46: icmp_seq=2 ttl=63 time=3.66 ms
^C
--- 192.0.2.46 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 3.662/7.965/12.268/4.303 ms
Additionally, the seed VM has extracted a public keys for SSH access to all the nodes, therefore you can also SSH to the nova “demo” VM:
root@hLinux:~# ssh 192.0.2.46
The authenticity of host '192.0.2.46 (192.0.2.46)' can't be established.
ECDSA key fingerprint is f8:64:aa:0c:77:95:db:7c:d7:0a:4d:e2:50:e1:b9:d9.
Are you sure you want to continue connecting (yes/no)? yes
root@demo:~#
In the host system (in my Lab called HPHelion1), we can check what is actually all running here. First, I noticed in the standard top command, that 4x qemu system is running and taking quite a lot of RAM, also the nova controller IP is pingable.
root@HPHelion1:/home/zerxen# ping 192.168.10.130
PING 192.168.10.130 (192.168.10.130) 56(84) bytes of data.
64 bytes from 192.168.10.130: icmp_seq=1 ttl=64 time=0.438 ms
64 bytes from 192.168.10.130: icmp_seq=2 ttl=64 time=0.400 ms
^C
--- 192.168.10.130 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.400/0.419/0.438/0.019 ms
root@HPHelion1:~# top
top - 18:49:35 up 2:04, 4 users, load average: 1.58, 3.98, 5.82
Tasks: 150 total, 2 running, 148 sleeping, 0 stopped, 0 zombie
%Cpu(s): 26.7 us, 0.8 sy, 0.0 ni, 71.0 id, 1.5 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 16371060 total, 16192012 used, 179048 free, 6184 buffers
KiB Swap: 11717628 total, 2261536 used, 9456092 free. 1229164 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3858 libvirt+ 20 0 6735060 4.002g 4652 S 3.7 25.6 7:09.02 qemu-system-x86
5119 libvirt+ 20 0 6743128 3.943g 4940 S 101.0 25.3 5:19.03 qemu-system-x86
4617 libvirt+ 20 0 6587532 3.926g 4644 S 1.9 25.1 3:42.09 qemu-system-x86
3171 libvirt+ 20 0 6689580 1.962g 4640 S 2.3 12.6 6:27.98 qemu-system-x86
766 root 10 -10 243044 32028 6404 S 0.0 0.2 0:06.61 ovs-vswitchd
1209 root 20 0 962388 6776 4756 S 0.0 0.0 0:01.81 libvirtd
Even better, using the virsh list command you can see the machines running our system
root@HPHelion1:/home/zerxen# virsh list
Id Name State
----------------------------------------------------
4 seed running
5 baremetal_0 running
6 baremetal_1 running
7 baremetal_3 running
Step 7: Connecting to the Horizon console
First, we have to get the keys, then list the nova controller for the horizon undercloud node IP like this.
root@hLinux:~# source ~root/tripleo/tripleo-undercloud-passwords
root@hLinux:~# TE_DATAFILE=~/tripleo/testenv.json
root@hLinux:~# source ~root/tripleo/tripleo-incubator/undercloudrc
root@hLinux:~# nova list
+--------------------------------------+-------------------------------------+--------+------------+-------------+---------------------+
| ID | Name | Status | Task State | Power State | Networks |
+--------------------------------------+-------------------------------------+--------+------------+-------------+---------------------+
| 1d51fdd8-468c-4988-b717-74a47e1f6914 | overcloud-NovaCompute0-4r2q45kefrrm | ACTIVE | - | Running | ctlplane=192.0.2.22 |
| 30709eb7-511f-4bea-bcfa-58b7ee01c9cf | overcloud-controller0-6yxubmu4x2eg | ACTIVE | - | Running | ctlplane=192.0.2.23 |
+--------------------------------------+-------------------------------------+--------+------------+-------------+---------------------+
Notice that we now see two different machines, one is using 192.0.2.22 and the second using 192.0.2.23. These two boxes are the “overcloud” and for horizon console, we need to connect to the overcloud-controller.
The passwords were automatically generated during installation, to read them, open this file ~root/tripleo/tripleo-overcloud-passwords.
root@hLinux:~# cat ~root/tripleo/tripleo-overcloud-passwords
OVERCLOUD_ADMIN_TOKEN=e7d24cc02607fa6ecdcaab72d7b40e5a0212365b
OVERCLOUD_ADMIN_PASSWORD=2f1d8666540c6cb192b0f74fadbce32eff2f3493
OVERCLOUD_CEILOMETER_PASSWORD=a07f05b1730eac806f9391b3ef1167b0905c5121
OVERCLOUD_CINDER_PASSWORD=e42d485c675ca118e43486b8dbc2ff2cb061e9c0
OVERCLOUD_GLANCE_PASSWORD=85b347e23fd022076f488c166e44596461515b2e
OVERCLOUD_HEAT_PASSWORD=ab4a3b2a73fc874501f189a2c3e06e40025d3ea0
OVERCLOUD_NEUTRON_PASSWORD=11e26addc33a2f7ab79788ed6eb92ee6d911ea81
OVERCLOUD_NOVA_PASSWORD=5a90eb1c6a3ef73d671f72fe47b7557e002eb42e
OVERCLOUD_SWIFT_PASSWORD=9e05710e7d8bd24aeeb91e2d44f81f2fd6cc8fd0
OVERCLOUD_SWIFT_HASH=1b95f901113e32d8b7cdd3e046207d657660f750
OVERCLOUD_DEMO_PASSWORD=a304b9d3c3d9def5c4978ed7f0ca3e622a5d6f1c
For horizon dashboards, note the OVERCLOUD_DEMO_PASSWORD and OVERCLOUD_ADMIN_PASSWORD.
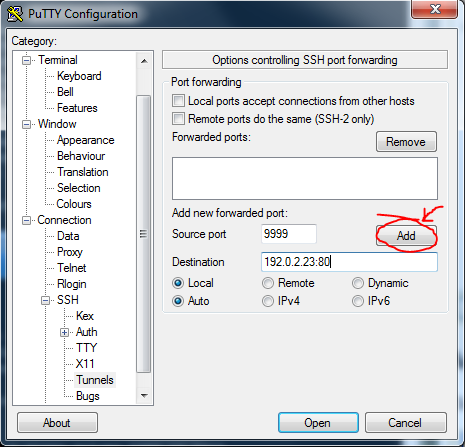
If you have installed the HPHelion on your host ubuntu and you are sitting in front of this box with graphical environment present, you can now simply open a web-browser and go to http://192.0.2.23/, in my case, the LAB is remote and I only have access to the host ubuntu as a server, so for me the 192.x.x.x IPs are behind it, however a classical reverse SSH tunnel solved this for me (actually the idea is from HP Helion install guide).
For linux:
ssh -L 9999:<IP of overcloud controller>:80:<hostname or IP of remote system>
In windows, you can use putty for this:
![putty_forwarding]()
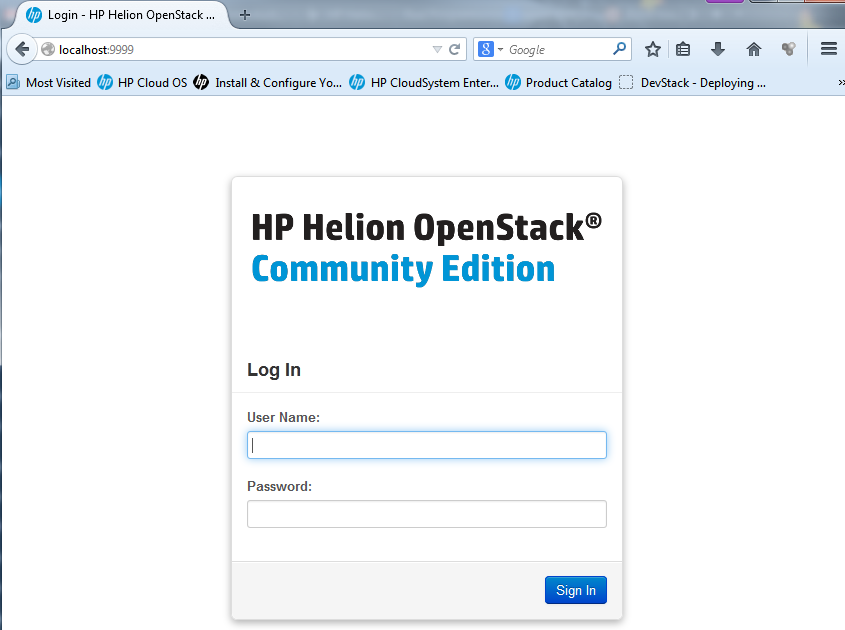
Then you can finally open a web-browser and enter the fabulous Horizon console (yes, exaggerating as I spent getting to this point around 8 hours of various lab issues) either directly or in my case I used SSH forwarder in localhost:9999 as mentioned above with putty.
![HP Helion login screen]()
HP Helion login screen
![HP Helion first time look to the dashboard]()
HP Helion first time look to the dashboard
Testing (or “playing with”) HP Helion horizon dashboard
Ok, lets have a look on all the main sections that appeared “by default”. First part is for a “Compute” which deals with everything related to running and managing all VMs.
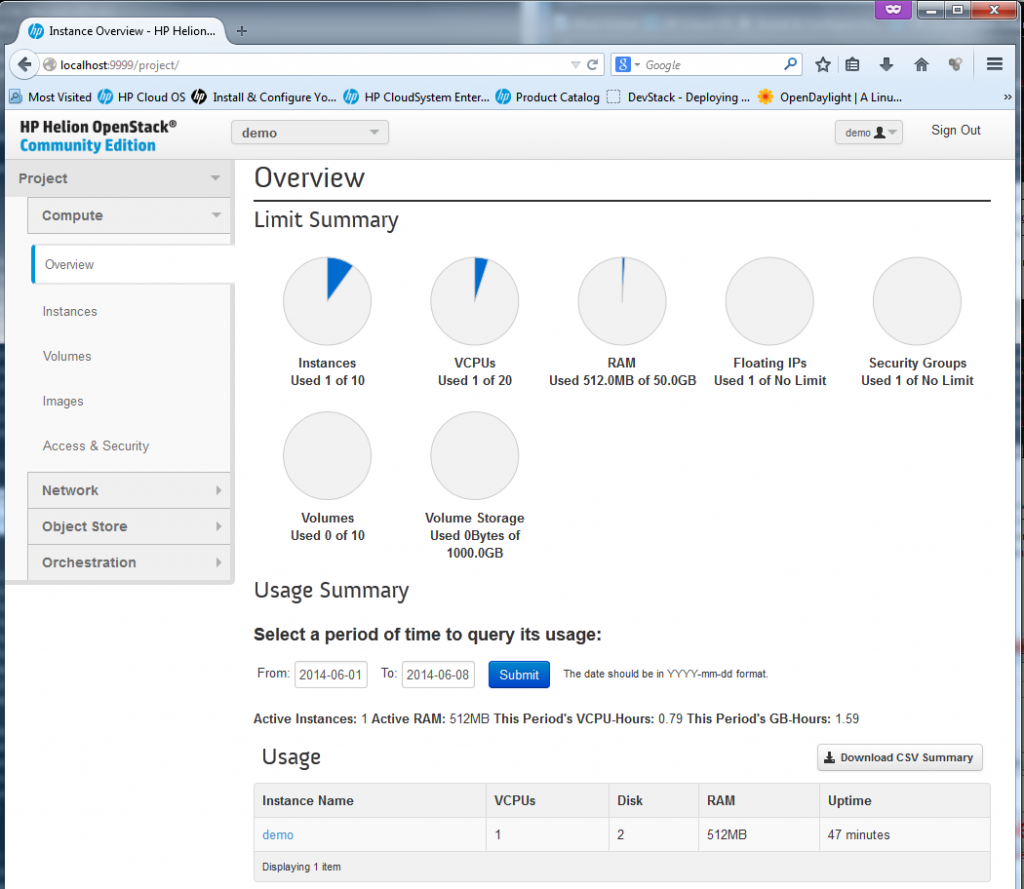
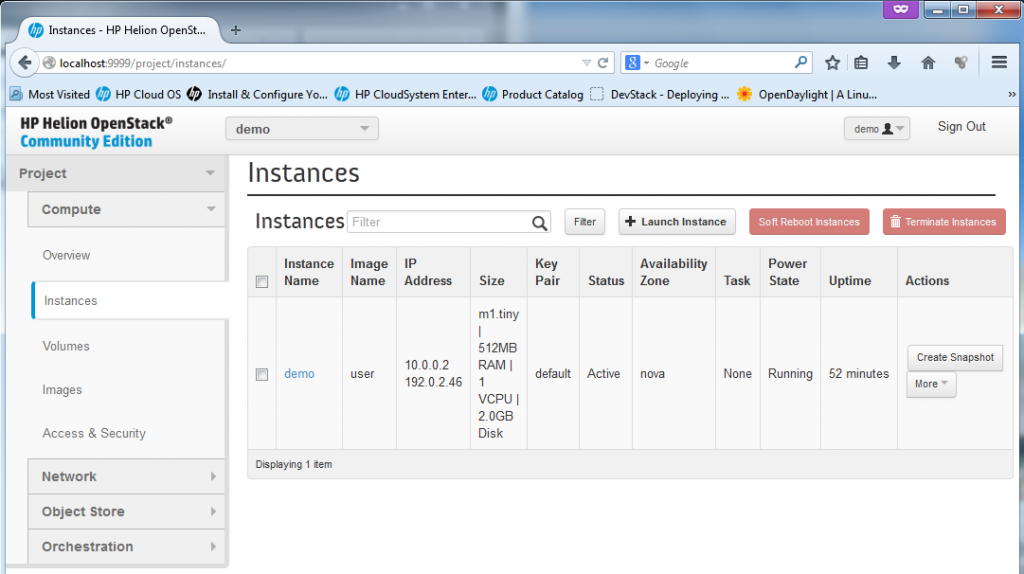
![Existing virtual machines or "instances", by default the HP Helion comes with the "demo" VM created.]()
Existing virtual machines or “instances”, by default the HP Helion comes with the “demo” VM created.
The Instances is the main view on the existing virtual machines in the “cloud”, by default HP Helion provided one “demo” box as example. The box already has a floating IP assigned to it. We will play much more in this section later.
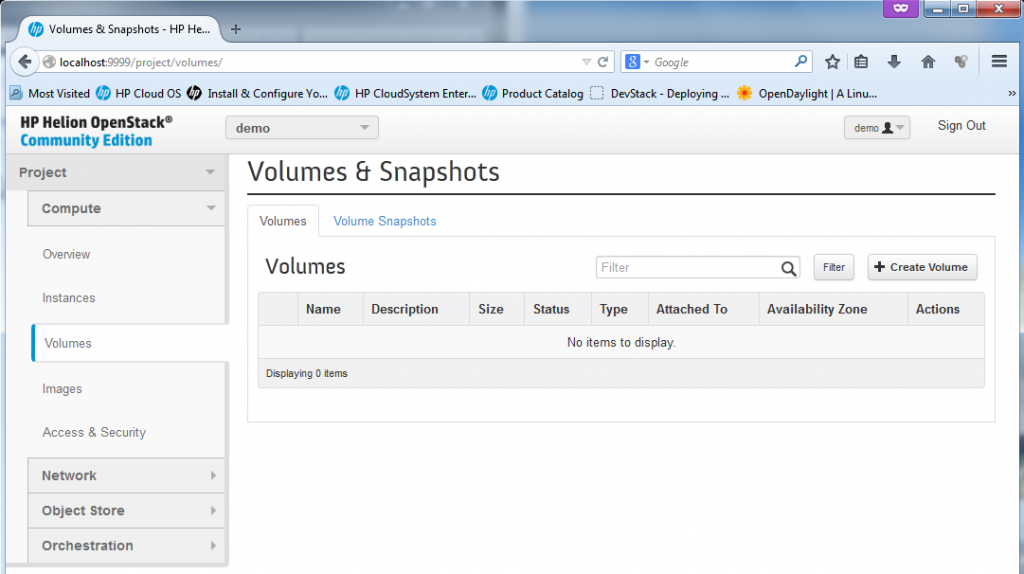
![The "volumes" section is quite empty, the volumes is a place where dynamically mounted storage can be created.]()
The “volumes” section is quite empty, the volumes is a place where dynamically mounted storage can be created.
Tho volumes are used for dynamic block storage, it is a generic storage that can be mounted/unmounted dynamically to virtual machines. Foe example for linux the storage would appear as /dev/sdX and can be universally mounted.
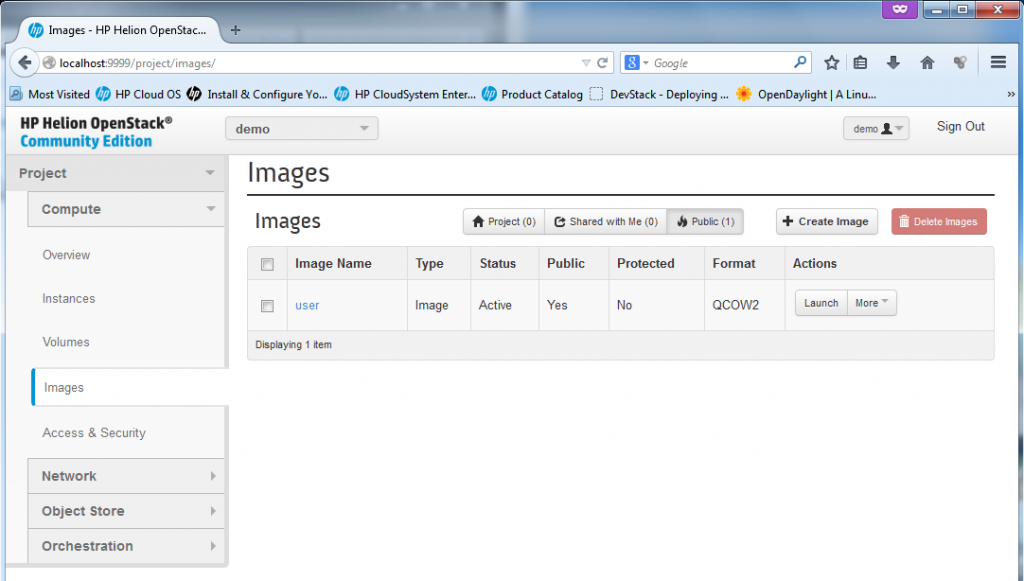
![The images section enables management of "template" images for new VM creation]()
The images section enables management of “template” images for new VM creation
The images section is where the VM creation automation can happen, by default the HP Helion comes with one image called “user” in QCOW2 format. You can find files for this image in the installation scripts if you wish to learn how to create your own.
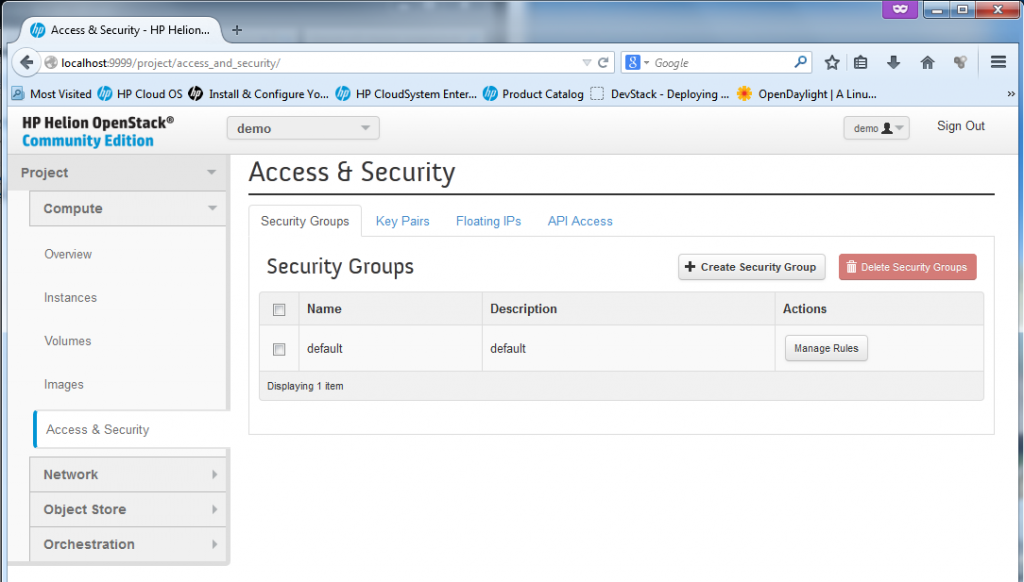
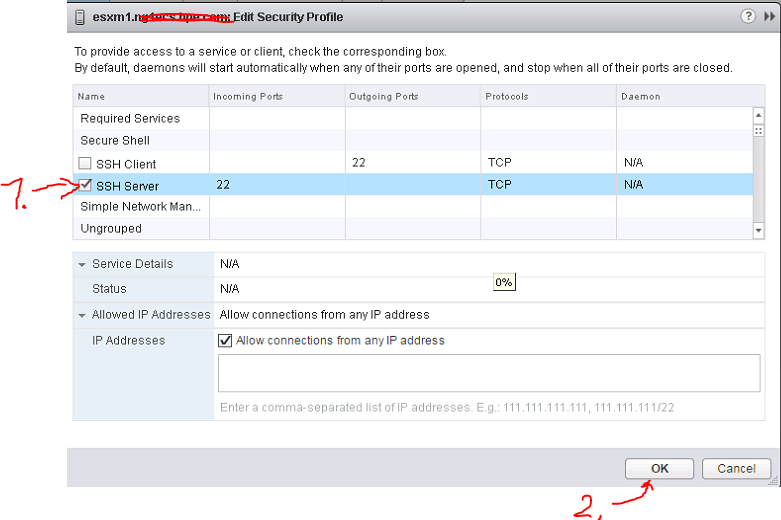
![The security section for management of access rules (technically firewall rules) for each VM.]()
The security section for management of access rules (technically firewall rules) for each VM
The security section is used for thee main things.
1) Firewall rules for port access to each VM
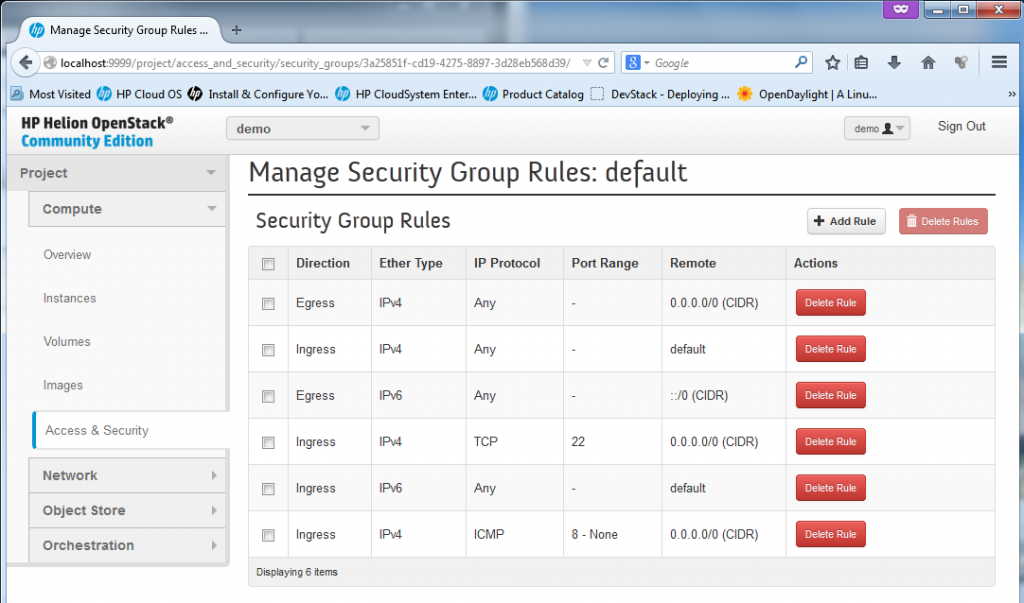
![Firewall rules management in OpenStack with creation of "access groups"]()
Firewall rules management in OpenStack with creation of “security group rules”
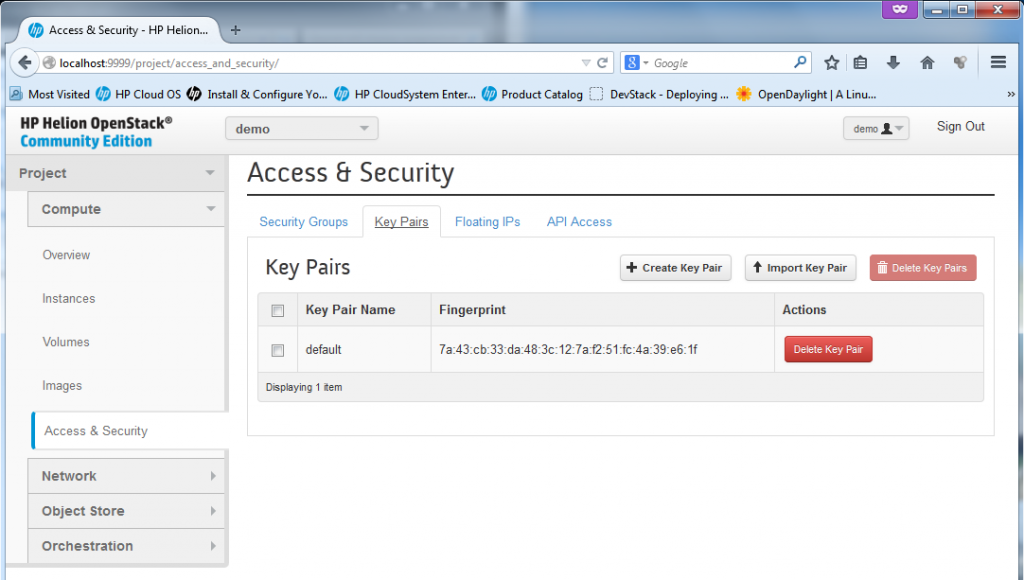
2) Management of private/public keypairs. OpenStack utilizes (or let’s say prefers) using SSH keys for access to servers (or at least to all *nix systems), therefore management of such keys is needed in Horizon and it is found here in Access&Security section. PS: By default the Horizon only wants the public key from you, so you can keep the private one on your PC and do not expose it! By default the HP Helion will use the keys which we originally created at the very beginning by ssh-keygen,
![SSH private/public key pairs management]()
SSH private/public key pairs management
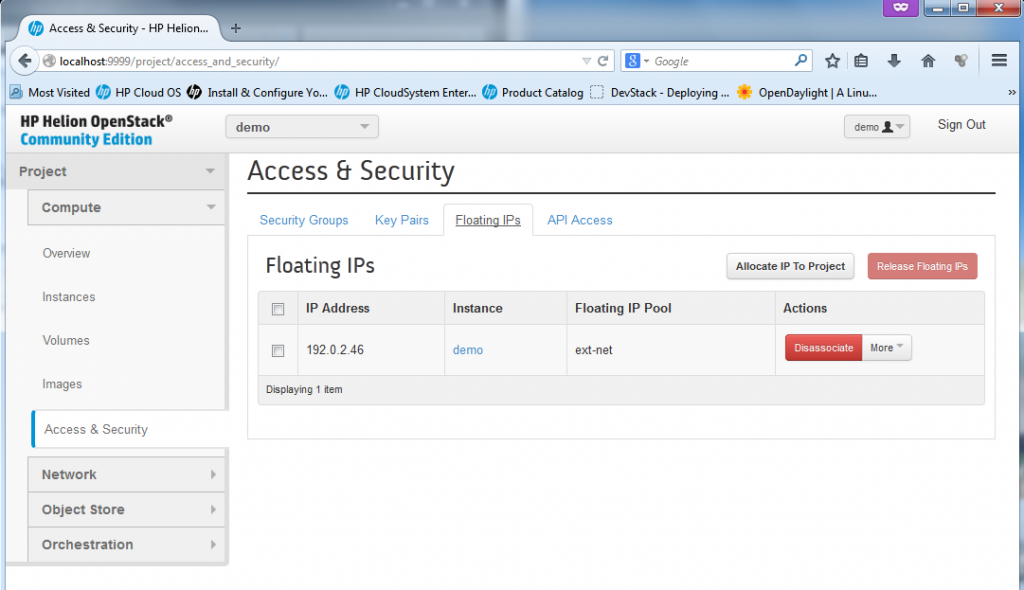
3) Management of floating IPs. A floating IP is a NAT IP given to a server so that the server can be reachable from the “outside” which means from the hosting server, or even from any external networks outside of cloud. You will see example IP provided later below.
![Floating IP management]()
Floating IP management
Following the security as last section in the “Compute”, we can now move to the “Network” part. In the basic HP Helion installation, there exists the ext-net defined as 192.0.2.0/24 which provides the publicly reachable IPs (or should be in production environment) and then one default-net with internal IPs of 10.0.0.0/24.
![Basic HP Helion network topology (the router with 10.0.0.1 connecting ext-net and default-net is missing as a bug)]()
Basic HP Helion network topology (the router with 10.0.0.1 connecting ext-net and default-net is missing because the routers is under ADMIN!!)
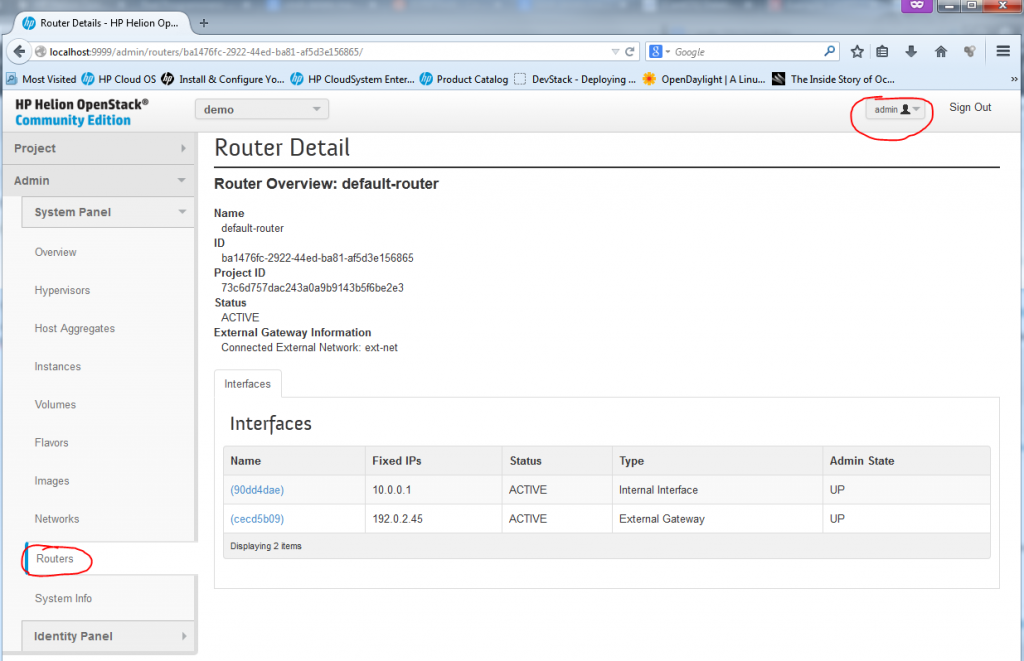
REMARK: The router between default-net and ext-net exists! But it is created by default under ADMIN account, if you want to see it, log-out the demo account and login as admin. Then in the routers section, you will see a router with two interfaces, one to ext-net and another to default-net. He is a look on it under Admin -> System Panel -> Routers:
![Default router between default-net and ext-net hidden under administrative login]()
Default router between default-net and ext-net hidden under administrative login
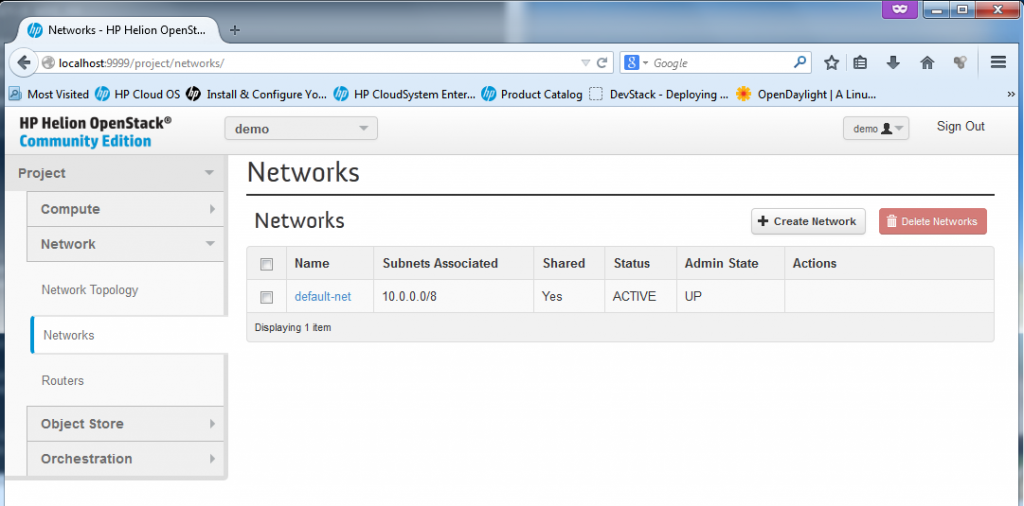
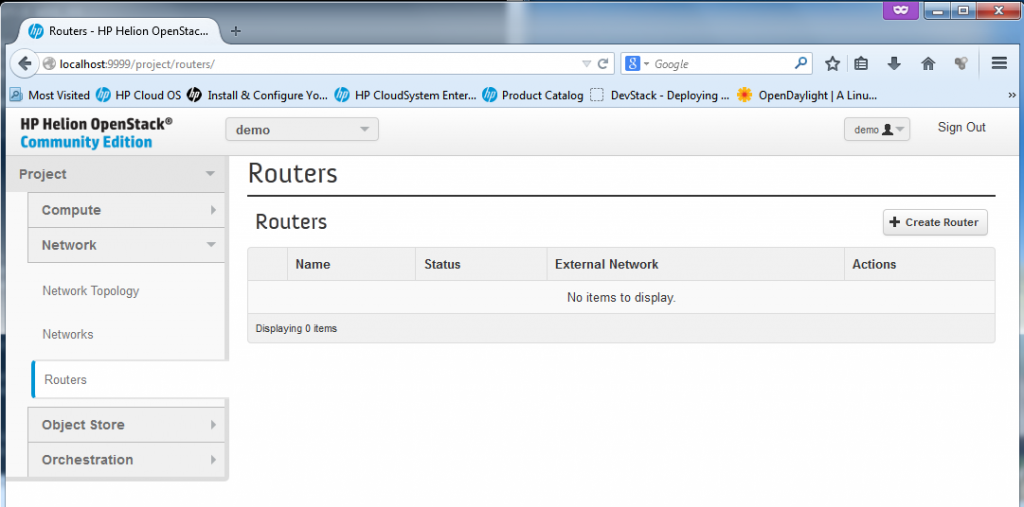
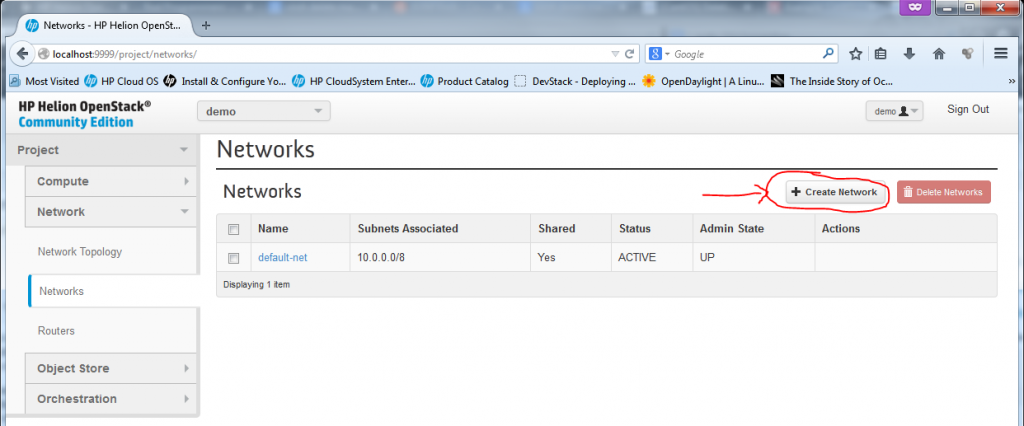
There is also a management page for definitions of “Networks” and “Routers”, in these two you can create for your new VMs multiples independent subnets and interconnects between them, I will go in details to each later below.
![Network definitions in HP Helion]()
Network definitions in HP Helion
![Routers definition in HP Helion]()
Routers definition in HP Helion (see REMARK above for the default router hidden under “admin” login)
Creating a new Instance
Part 1 – “Launch Instance”, VM parameters
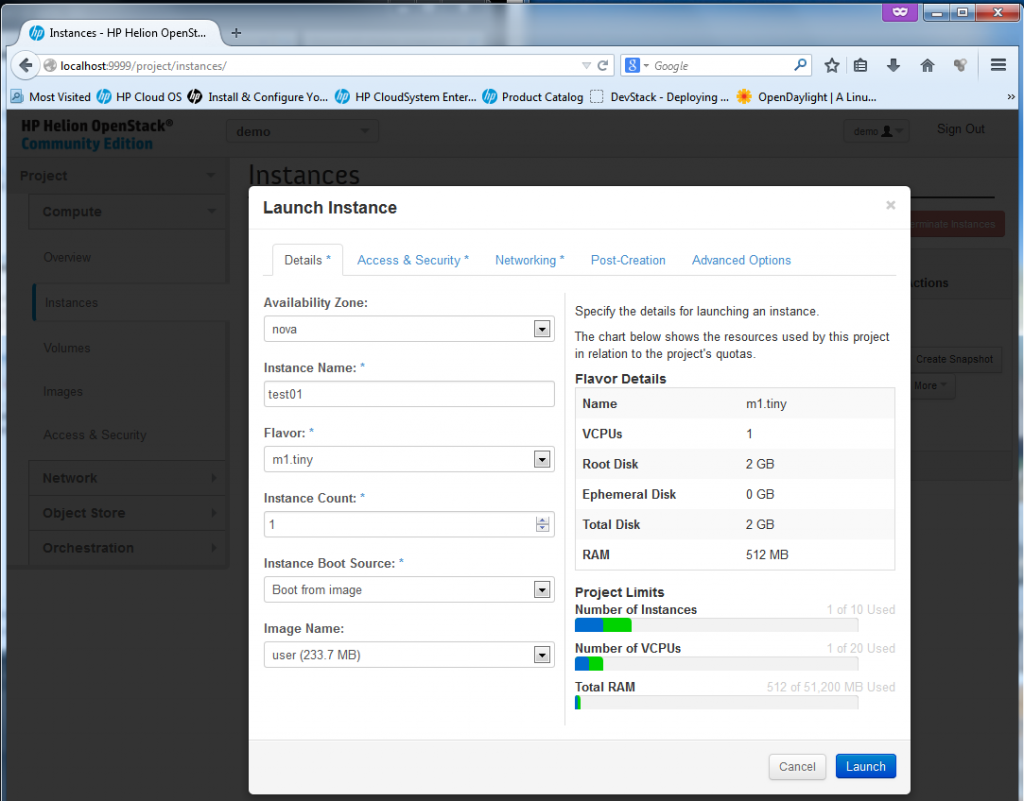
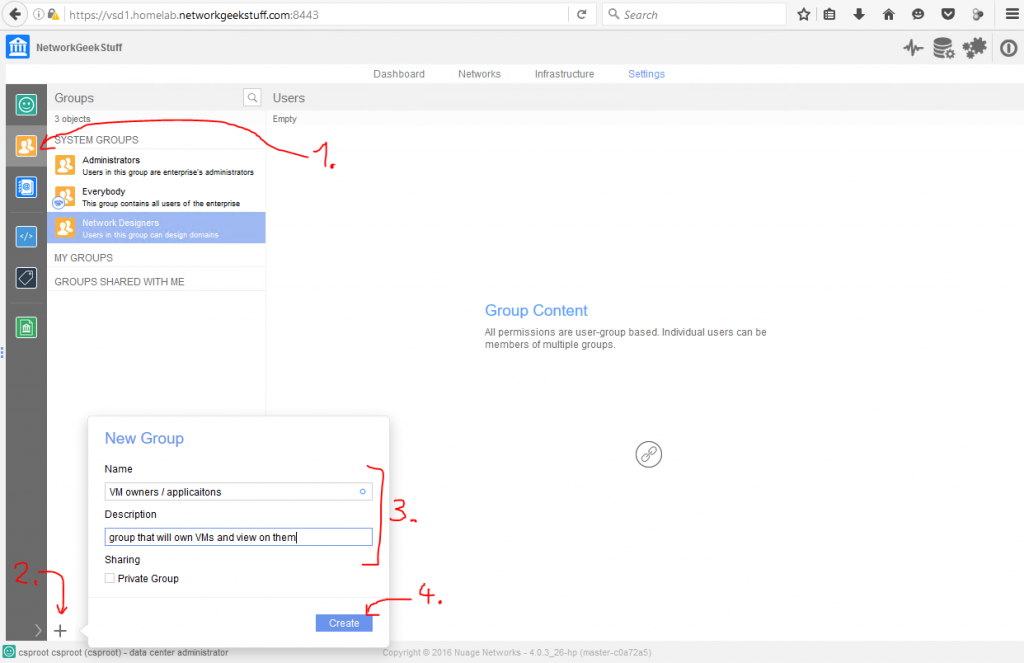
Ok, you have seen the “Instance” section under “Compute” above, now lets try to create quickly one new virtual machine there. Lets start by returning to Compute->Instances and select “Launch Instance“. I will create a new instance called “test01″, it will be a minimal image (because really, my server doesn’t have much RAM or CPU resources left).
![Creating new Instance, part 1 - resource allocation, image selection]()
Creating new Instance, part 1 – resource allocation, image selection
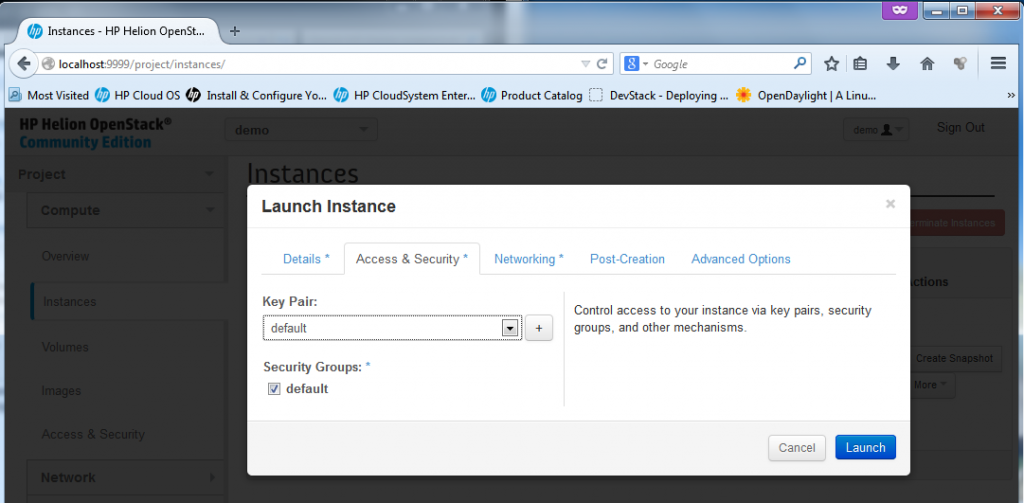
Part 2 – Launch Instance – keypair and security group
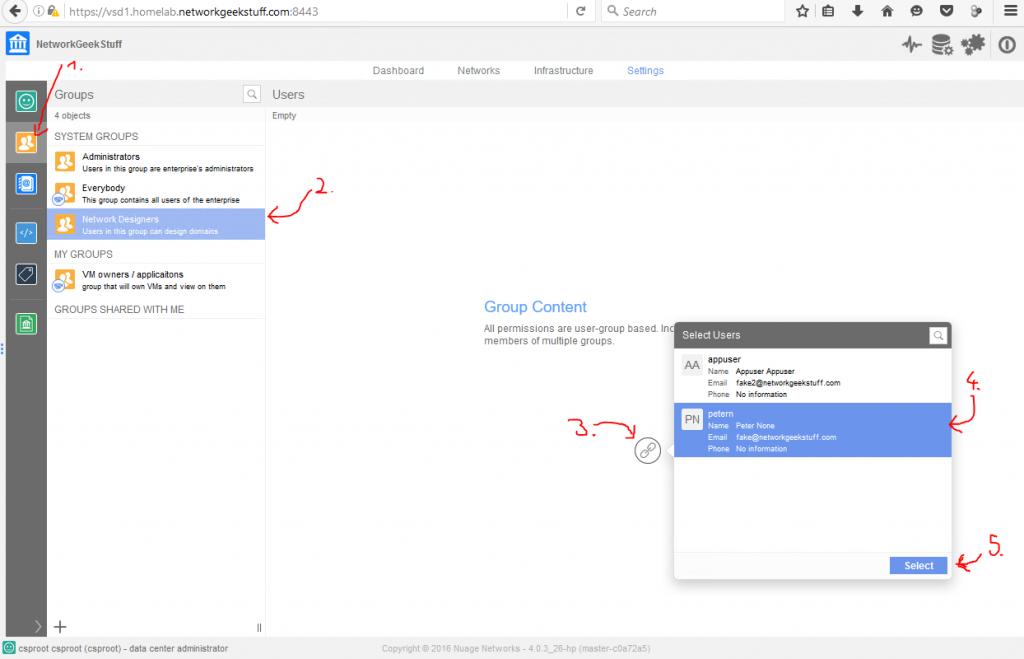
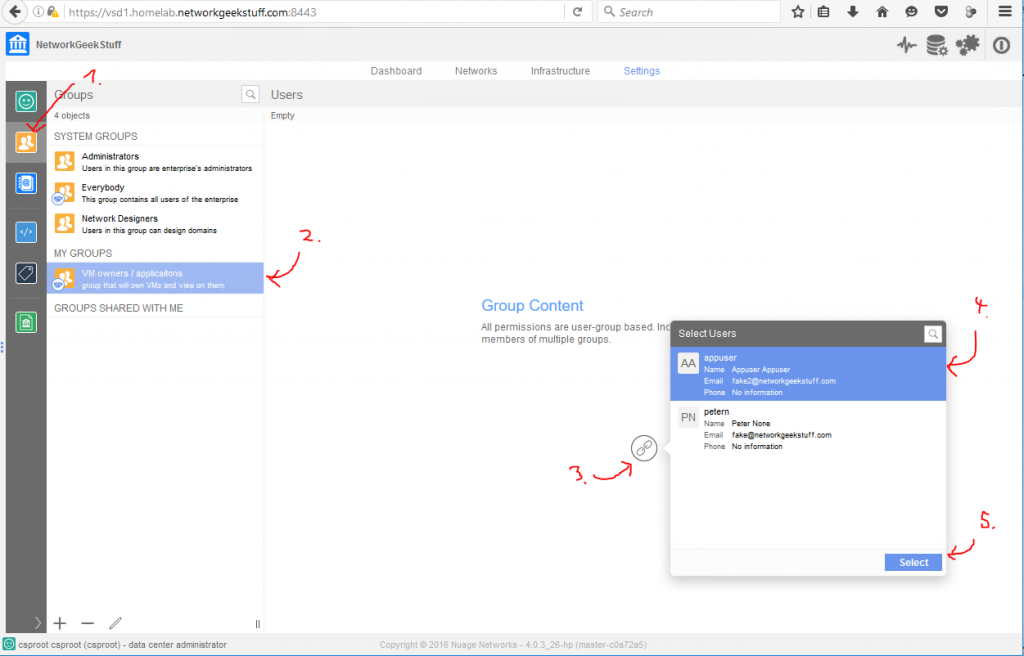
Next we have to define the Access&Security, I do not plan to change the default FW rules as the ping and SSH is allowed there (see previous section screenshots). So I will go with the defaults here, including the default keypair.
![Creating new Instance, part 1 - security rules]()
Creating new Instance, part 2 – security rules
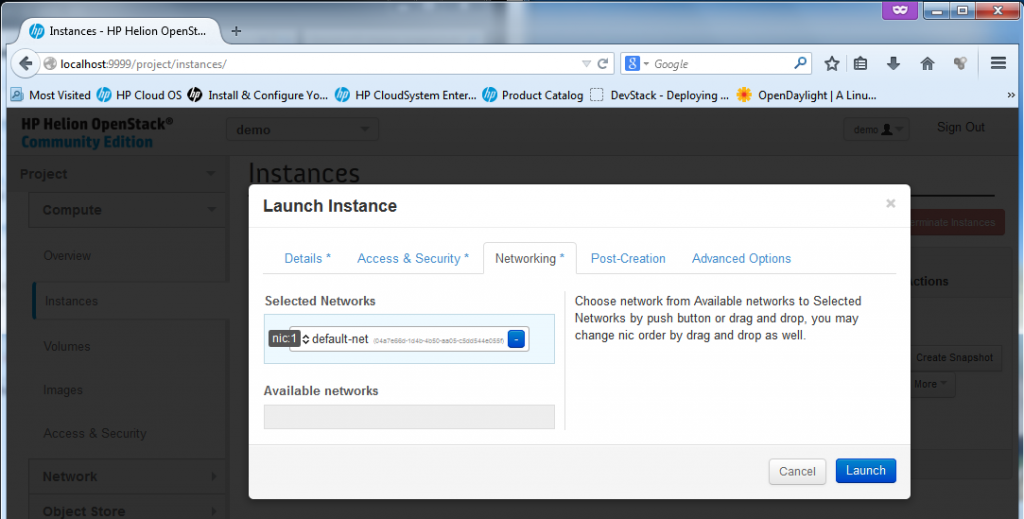
Part 3 – Launch Instance – Network interface
Last part that is worth mentioning is Networking (because I will skip the “Post-Creation” and “Advanced Options” sections as uninteresting – really, these are for self-explanatory and I am currently not needing to go into them). In Networking you can choose the interfaces/subnets where your new VM should be connected to. Because we didn’t yet went into the Network section (this we will do in next section), I will only go with the default-net here.
![Creating new Instance, part 3 - Network selection]()
Creating new Instance, part 3 – Network selection
Part 4 – Launch Instance – Spawning new VM
Click “Launch”, the new VM will start to “spawn… ” for a while….
![Creating new Instance, part 4 - spawning ...]()
Creating new Instance, part 4 – spawning …
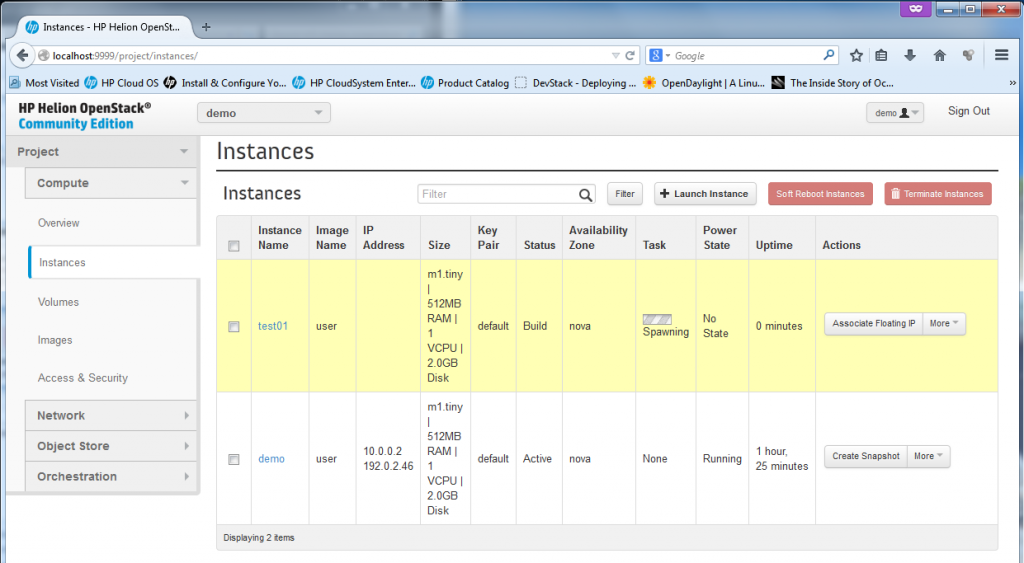
Once the spawning finishes, the VM is ready, the state will just change to “Running” … but at this point, it will only have the default-net IP of 10.0.0.x, but no floating IP yet, but this is OK.
![Creating new Instance, part 5 - new VM "test01" ready]()
Creating new Instance, part 4 – new VM “test01″ ready
On the console level, you can also check your instance exists, by going to the compute node (in my case the 192.0.2.22 – go back to Installation section, step #7 on how to find your compute node IP), the compute node is running KVM hypervisor so you can simply use the # virsh list command to list the instances, right now you should have there two instances created (first is the existing “demo” and the second one is the new “test01″. This is my example how I went there from the host system, first SSH is to the seed VM (because it has all the SSH keys) and then to the novacompute0 VM and changing to root (sudo su – is without password on cloud systems).
root@HPHelion1:~# ssh 192.0.2.1
<omitted>
root@hLinux:~# ssh heat-admin@192.0.2.22
<omitted>
$ sudo su -
root@overcloud-novacompute0-4r2q45kefrrm:~# virsh list
setlocale: No such file or directory
Id Name State
----------------------------------------------------
2 instance-00000001 running
4 instance-00000003 running
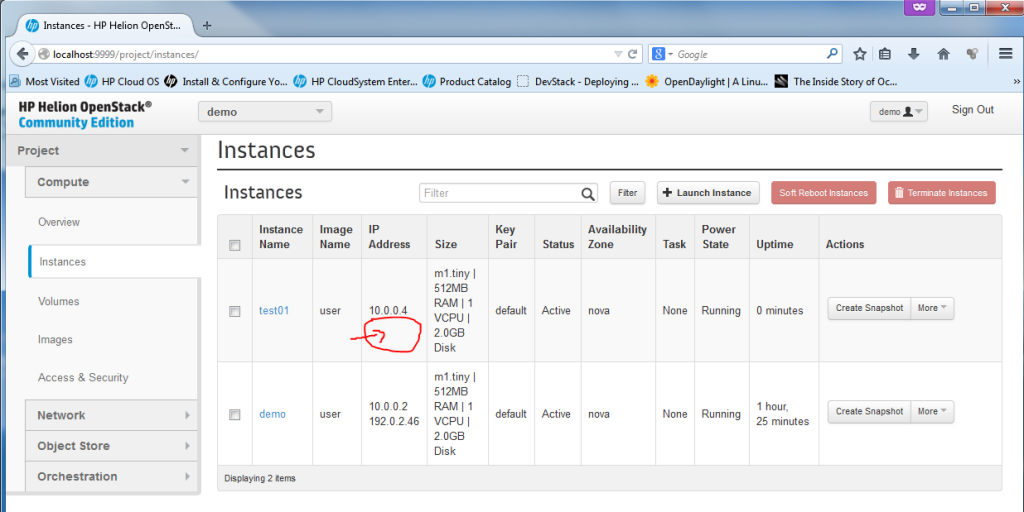
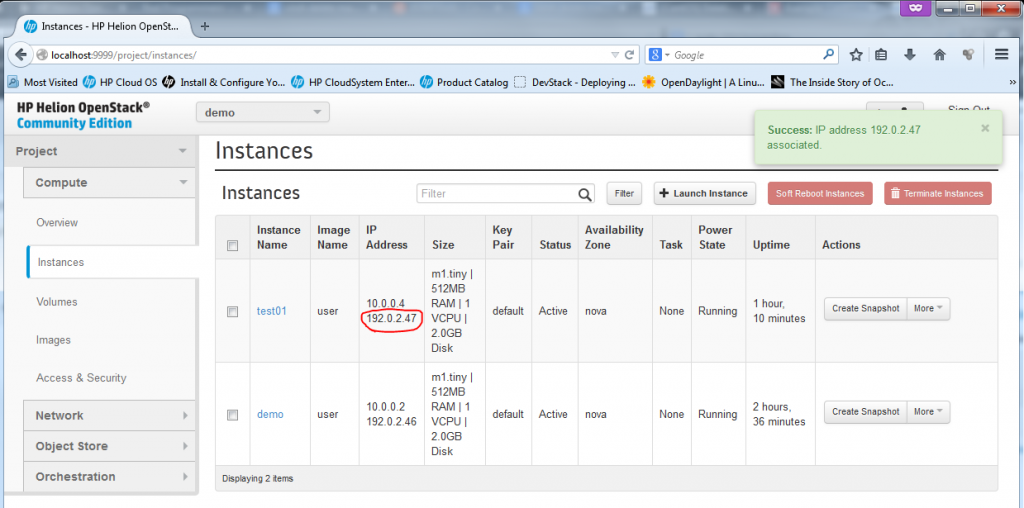
Part 5 – Launch Instance – Allocating and Associating a Floating IP with new VM (Optional step)
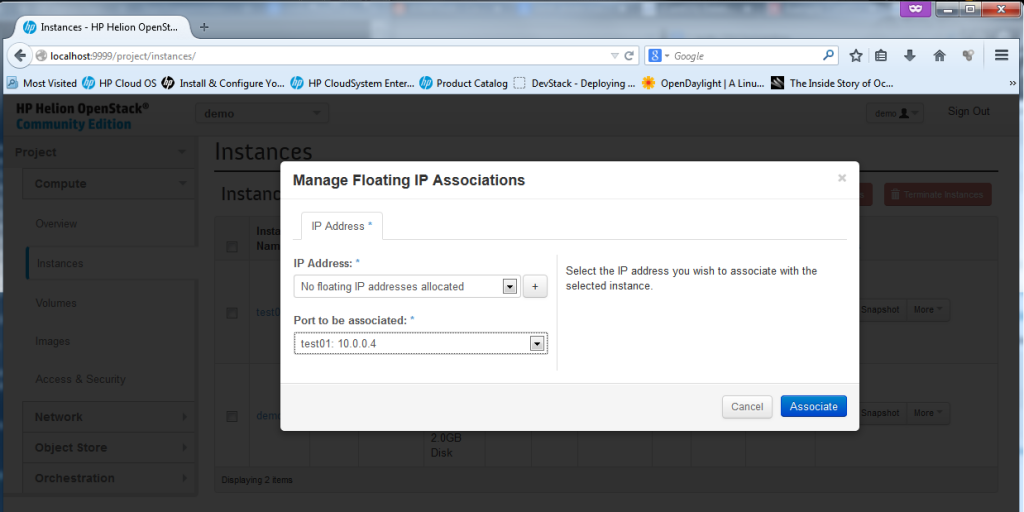
To assign a machine a floating IP, just go to the drop-down menu “More” and select “Associate Floating IP”. A small dialog will appear where you can select a port to associate with a new floating IP, select the “test01-10.0.0.4″, and hit the plus sign ” + ” to first allocate a new floating IP from a pool.
![Creating new Instance, part 6 - floating IP dialog]()
Creating new Instance, part 5 – floating IP dialog
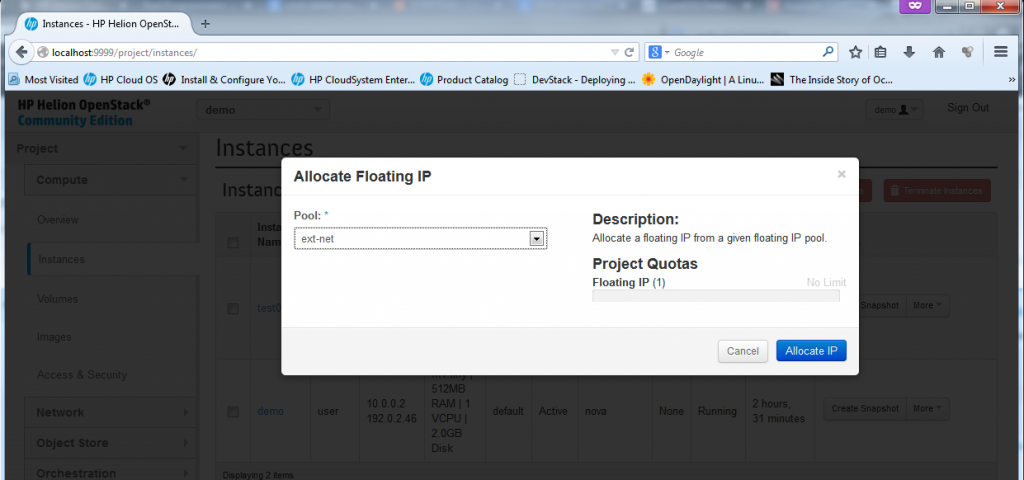
![Creating new Instance, part 6 - allocate from a pool]()
Creating new Instance, part 5 – allocate from a pool
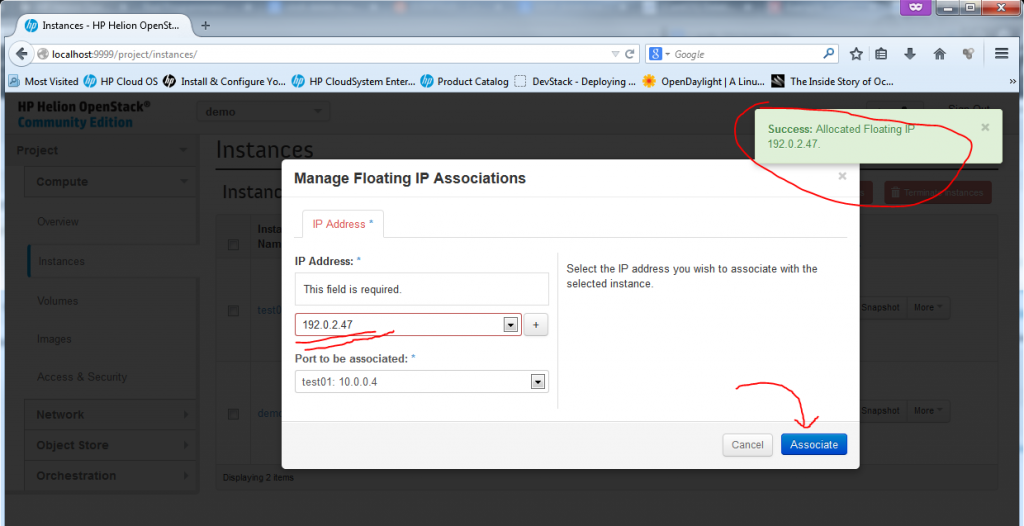
![Creating new Instance, part 6 - Floating IP allocated, just hit "Associate"]()
Creating new Instance, part 5 – Floating IP allocated, just hit “Associate”
Now, the VM is fully finished (well, technically if the machine didn’t had to be accessible from “outside”, you could have skipped the floating IP part), but now we have a fully finished second VM we can play with.
![Creating new Instance - FINAL]()
Creating new Instance – FINAL for “test01″, including new Floating IP
Verification of new Instance “test01″, access to console, network view
The basic test you can do if you have a floating IP is to ping it from the host ubuntu server, a quick ping should work.
root@HPHelion1:/home/zerxen# ping 192.0.2.47
PING 192.0.2.47 (192.0.2.47) 56(84) bytes of data.
64 bytes from 192.0.2.47: icmp_seq=1 ttl=62 time=9.08 ms
64 bytes from 192.0.2.47: icmp_seq=2 ttl=62 time=2.95 ms
64 bytes from 192.0.2.47: icmp_seq=3 ttl=62 time=2.17 ms
^C
--- 192.0.2.47 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 2.176/4.736/9.082/3.089 ms
For SSH access, on this point it is much more easy to go to the seed VM first, because this VM generated the keys, so you can jump from seed VM (hLinux) to all Helion VMs (both “demo” and new “test01″) without password because the private keys are exported.
root@HPHelion1:/home/zerxen# ssh 192.0.2.1
<omitted>
Last login: Sun Jun 8 15:57:53 2014 from 192.168.122.1
root@hLinux:~# ssh 192.0.2.47
The authenticity of host '192.0.2.47 (192.0.2.47)' can't be established.
ECDSA key fingerprint is 66:ac:fd:73:53:3e:1d:f6:db:e8:34:67:0f:46:cb:87.
Are you sure you want to continue connecting (yes/no)? yes
<omitted>
root@test01:~#
Of course, if you do not want to use the seed VM (hLinux) as jumpstation, just take the keys from its ~root/.ssh/ directory to the host system.
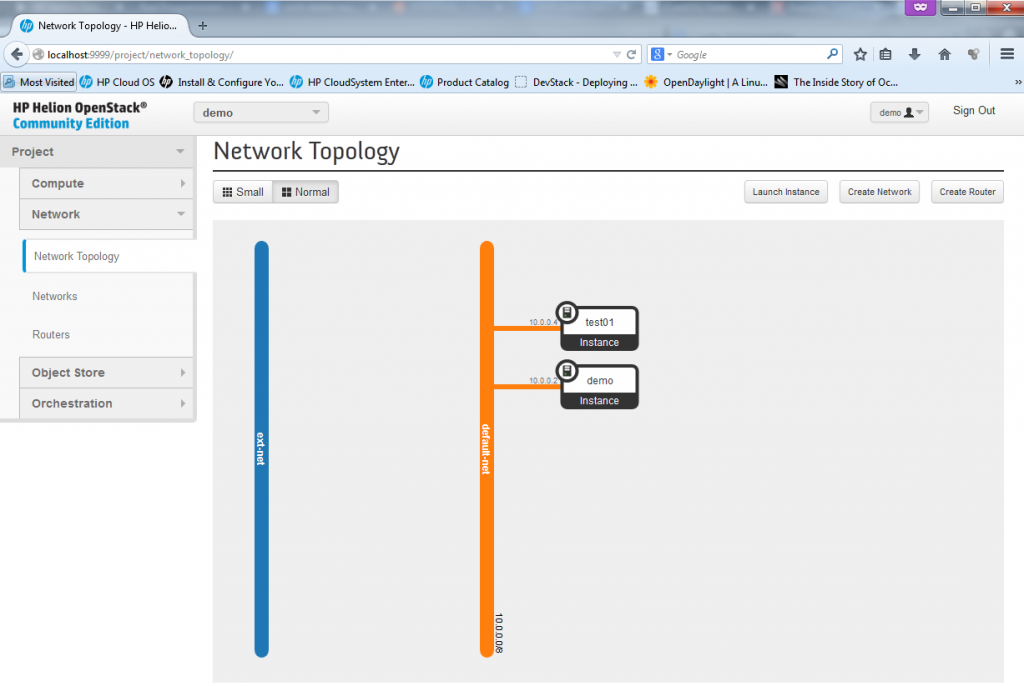
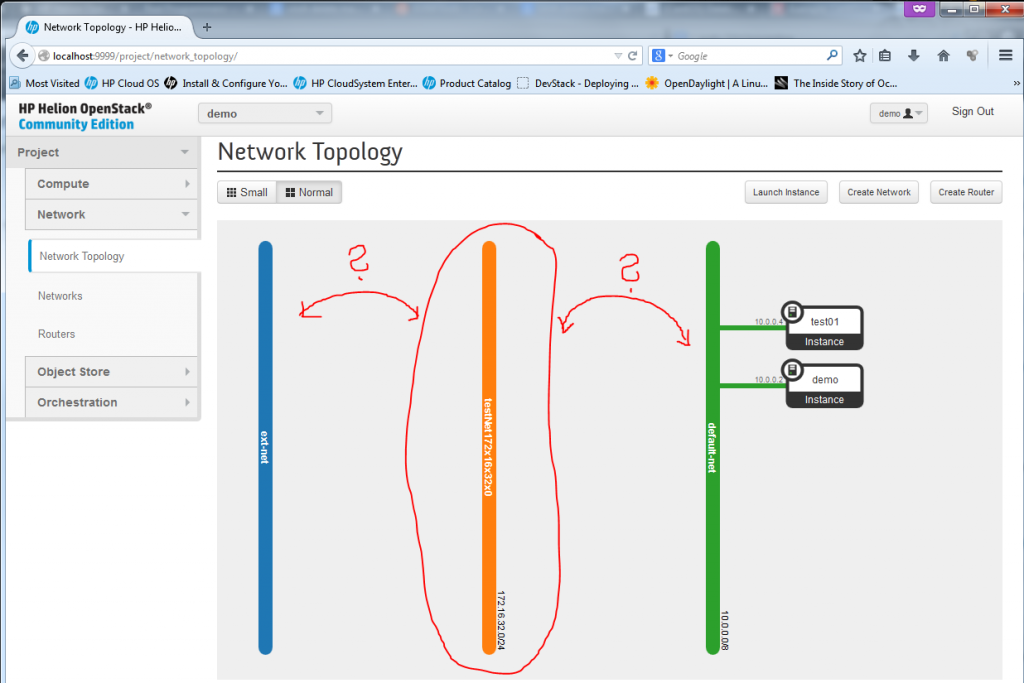
NOTE: You can also access the server using its 10.0.0.4 IP from a different servers inside the same subnet, so for example you can go to the “demo” VM and from it do an SSH towards 10.0.0.4, it will work just as normal because the two VMs are together part of the same subnet as shown below:
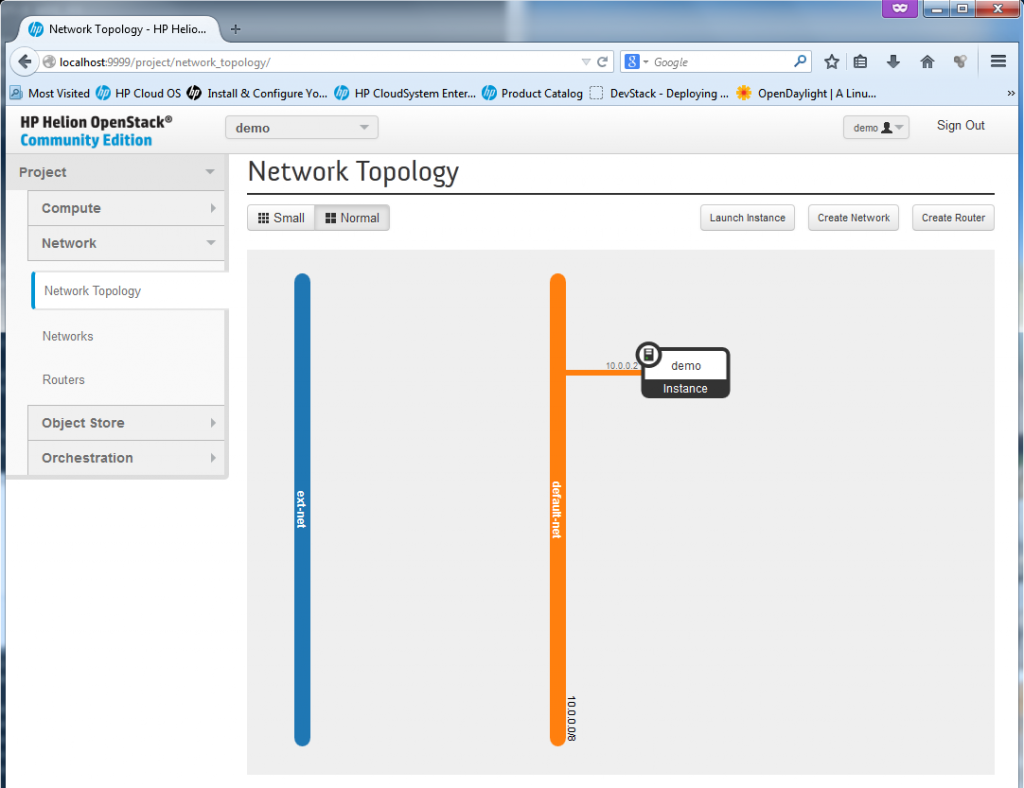
![Network topology view on both "demo" and "test01" VMs sharing the same subnet]()
Network topology view on both “demo” and “test01″ VMs sharing the same subnet
Creating new Network
In this part, I will show how easy it is to setup additional network, we will create a new subnet with IP range 172.16.32.0/24 and then also in the following section create a router between the default-net and our new network.
Part 1 – New Network – Open network creation dialog in Network -> Networks
![Creating new Network, part 1 - Opening "New Network" dialog]()
Creating new Network, part 1 – Opening “Create Network” dialog
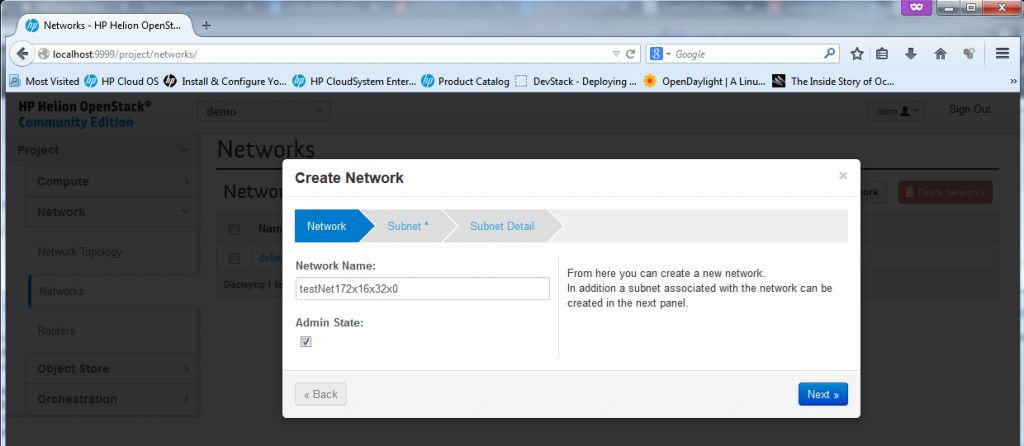
Part 2 – New Network – Give the new network a name
![Creating new Network, part 2 - give the network a name]()
Creating new Network, part 2 – give the network a name
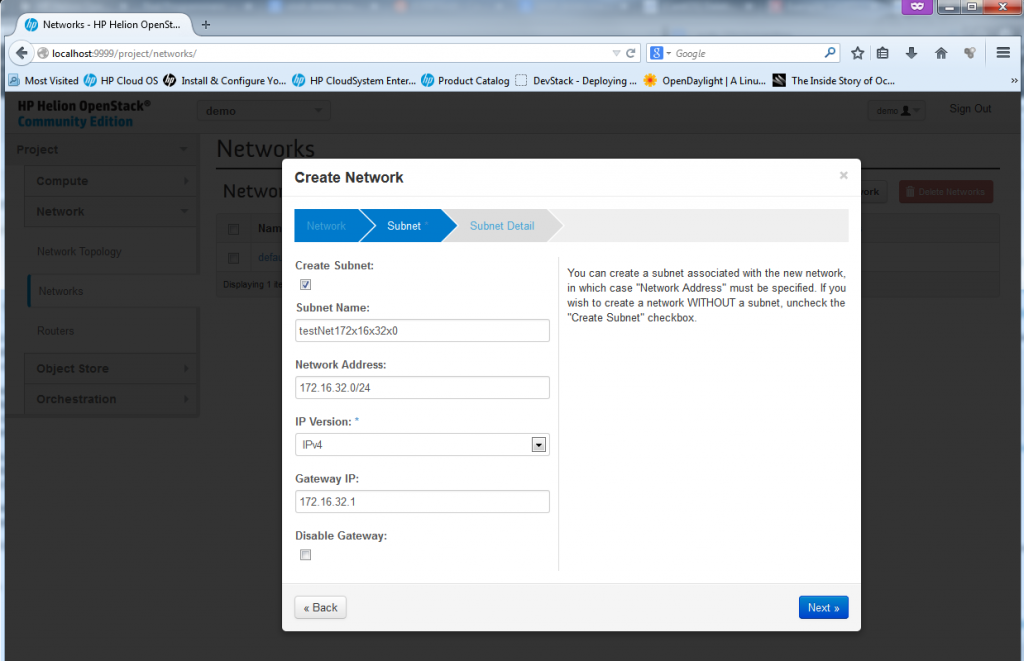
Part 3 – New Network – define the subnet/mask and optionally a default router/gateway
![Creating new Network, part 3 - Define network subnet parameters]()
Creating new Network, part 3 – Define network subnet parameters
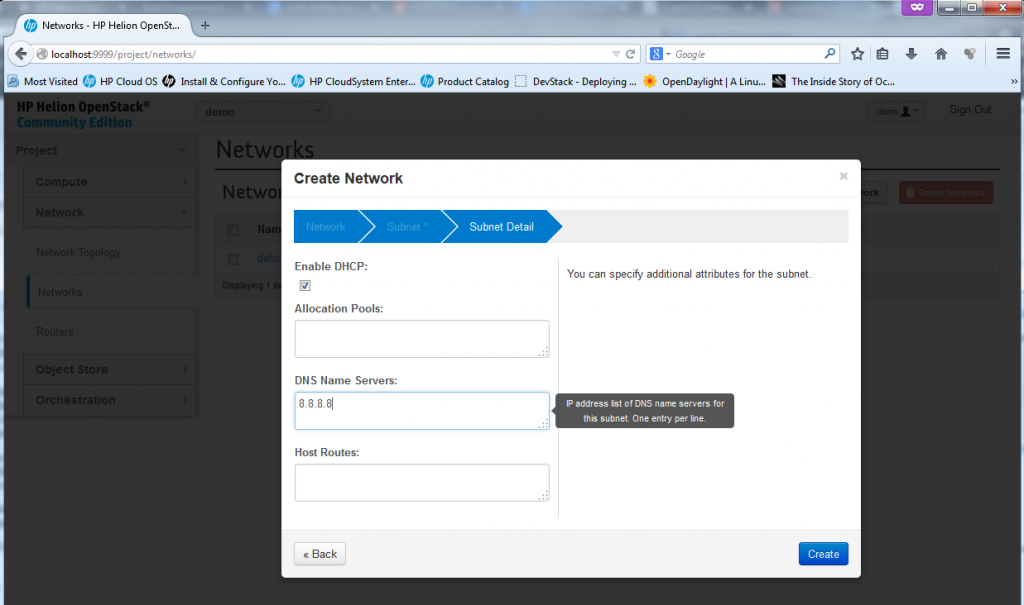
Part 4 – New Network – define DNS and other optional DHCP options
This is where you can define additional parameters like DNS and static routes, but for our use just add a DNS server if you have one in your LAB, or if you are using internet DNS like I am, I have used for LAB usage the google’s DNS on 8.8.8.8 (this is real Internet DNS, try it… ).
![Creating new Network, part 4 - DNS/DHCP options]()
Creating new Network, part 4 – DNS/DHCP options
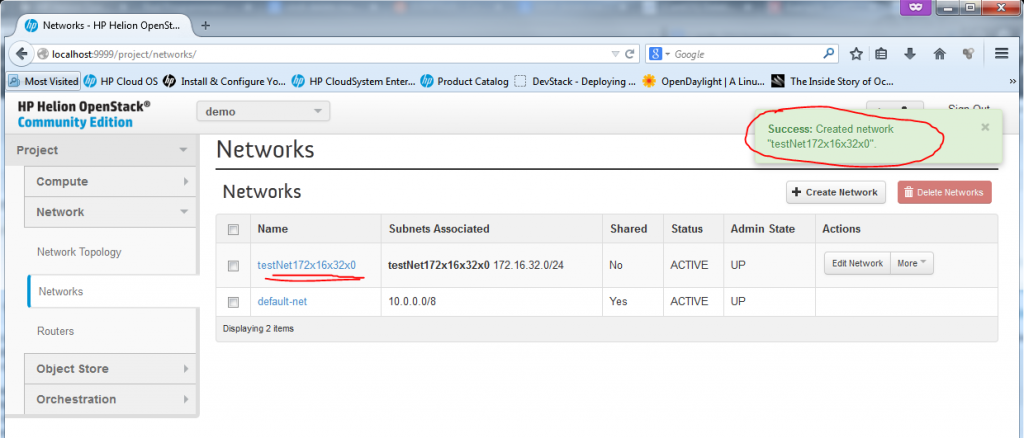
Part 5 – New Network – “was created”
Now the new network was created, and technically if you want you can already start putting new VMs/Instances with interfaces to this new network. At the moment, however, the new network is completelly disconnected from the other networks and we need a router to connect it.
![Creating new Network, part 5 - new network was created (and is ready to be used)]()
Creating new Network, part 5 – new network was created (and is ready to be used)
![Creating new Network, part 5 - New network exists, but disconnected]()
Creating new Network, part 5 – New network exists, but disconnected
What we need now is a router to interconnect our new 172.16.32.0/24 subnet with the default-net (10.0.0.0/8) and ext-net (192.0.2.0/24). This is what we will do in the next section.
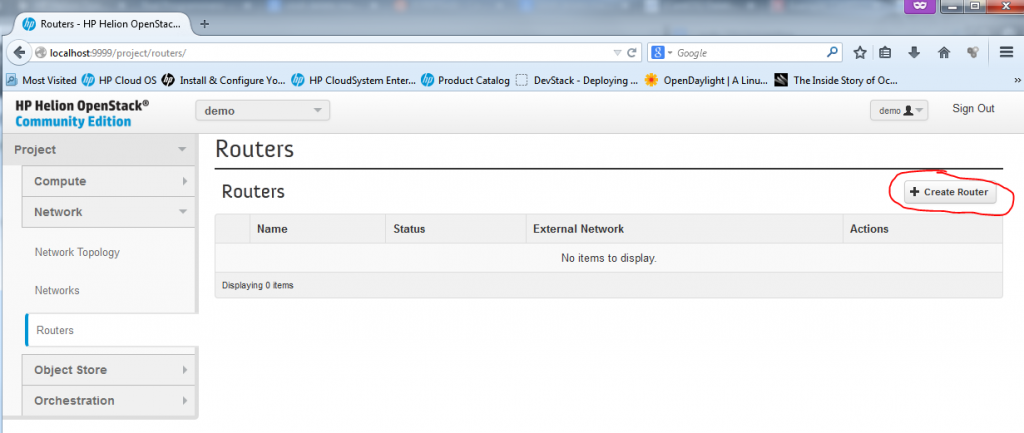
Creating New Router
It is quite silly how you can today create a virtual routers very simply, virtual routers are today used quite often in big server farms and this NFV (Network Function Virtualization) looks like is going to have a big success in cloud deployments. The obvious advantages for cloud are easy to imagine and having NFV functions technically moves cloud from their current “stupid server-farm” position to a really flexible environment where zones and DMZs is possible to create nearly instantly. I still cannot stop thinking about the high contrast between traditional typical DMZ orchestration project that usually takes 1-2 months and here you can have a functional DMZ in a few clicks. There are still things that need to get improved, for example, there is no Load-Balancer (or to be more exact, there is one in beta, but its capabilities are very limited in configuration scope).
But back on the task, creating a router in HP Helion, or OpenStack is quite easy, again just a few clicks via a dialog.
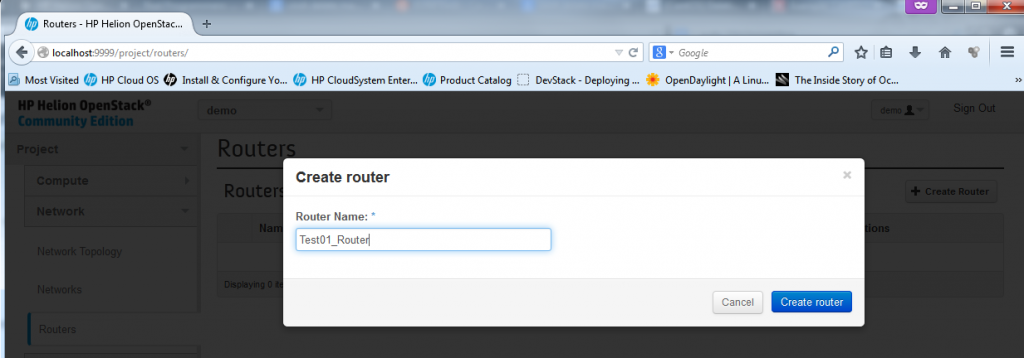
Part 1 – Creating New Router – starting the dialog and creating empty router “Test01_Router”
![Creating new Router, part 1 - starting new router dialog]()
Creating new Router, part 1 – starting new router dialog
![Creating new Router, part 1 - giving a name Test01_Router to new router]()
Creating new Router, part 1 – giving a name Test01_Router to new router
!["Creating]()
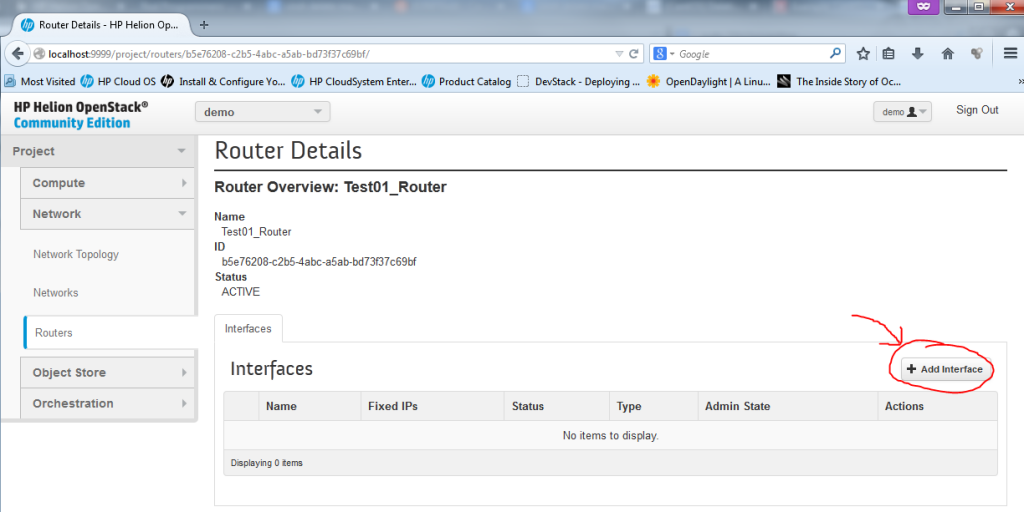
Part 2 – Create New Router – add interfaces to your router
Now we need to add interfaces to the router, to do this, in the router configuration we opened by clicking on the router name, we can select “Add Interface”
![Creating new Router, part 2 - Add Interface]()
Creating new Router, part 2 – Add Interface
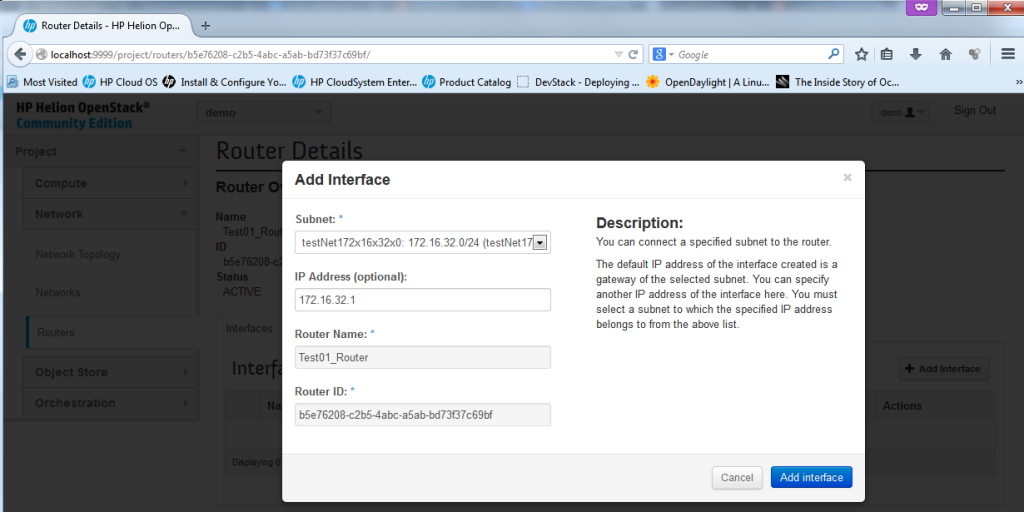
![Creating new Router, part 2 - Select Network for new Interface]()
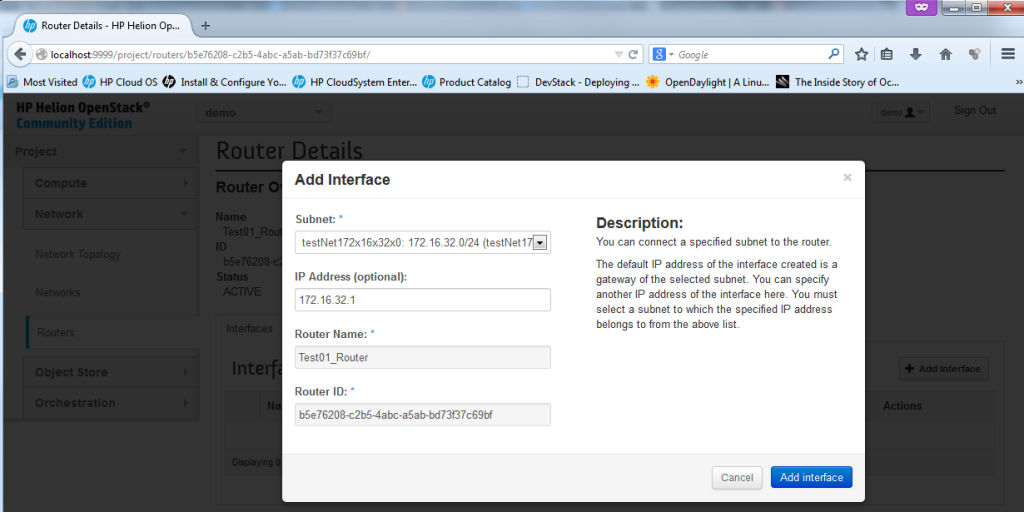
Creating new Router, part 2 – Select Network for new Interface – first the new 172.16.32.0/24
![Creating new Router, part 2 - Define IP address to give to the router (if there is a collision, the system will stop you)]()
Creating new Router, part 2 – Define IP address to give to the router (if there is a collision, the system will stop you)
Part 3 – Create New Router – Interface for global/shared subnets like ext-net and default-net
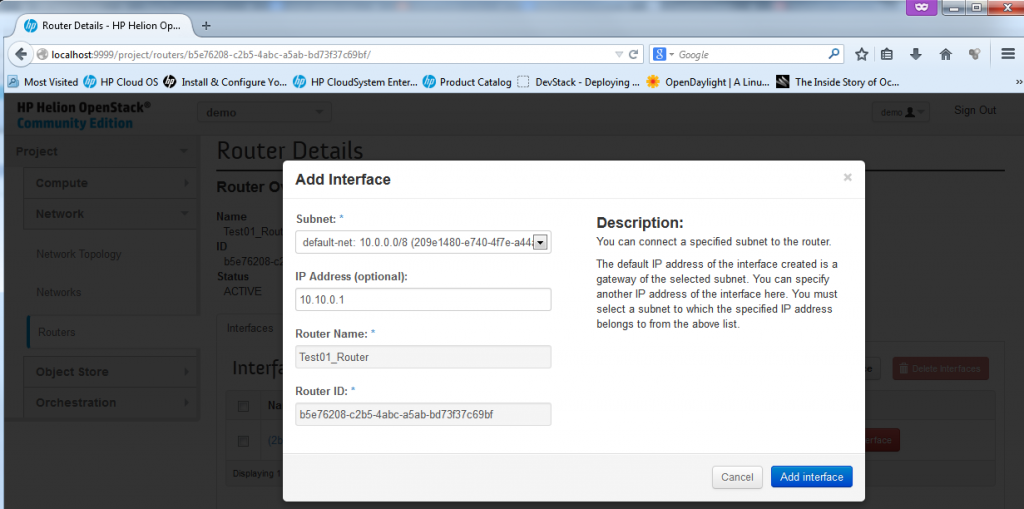
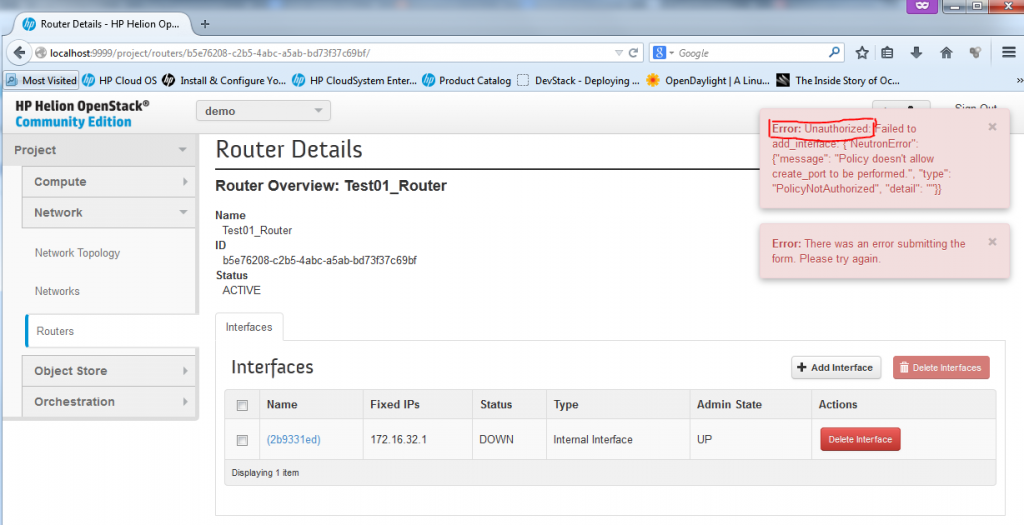
Unfortunately you cannot add interface towards the default subnets like the external ext-net and default-net because these are defined as common resource and only admin can add these, if you try to add an interface to the default-net 10.0.0.0/8 network, you will get the following error message:
![Creating new Router, part 3 - Define IP in admin interface (will cause error)]()
Creating new Router, part 3 – Define IP in admin interface (will cause error)
![Creating new Router, part 3 - Error when trying to add router interface to admin subnet]()
Creating new Router, part 3 – Error when trying to add router interface to admin subnet
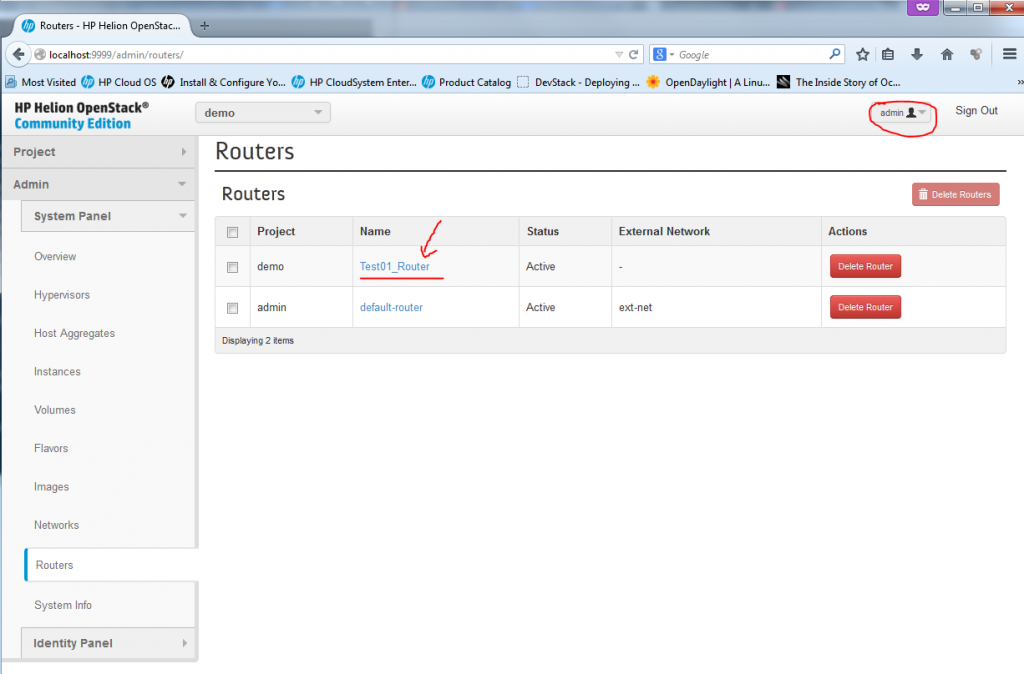
To avoid this issue, you have to add the interfaces as admin, so do a log-out, and login again as “admin” (The password you can get from reading your ~root/tripleo/tripleo-overcloud-passwords. and looking for OVERCLOUD_ADMIN_PASSWORD). In this admin mode, you can add router interface as intended.
![Creating new Router, part 3 - Admin configuration of router]()
Creating new Router, part 3 – Admin configuration of router
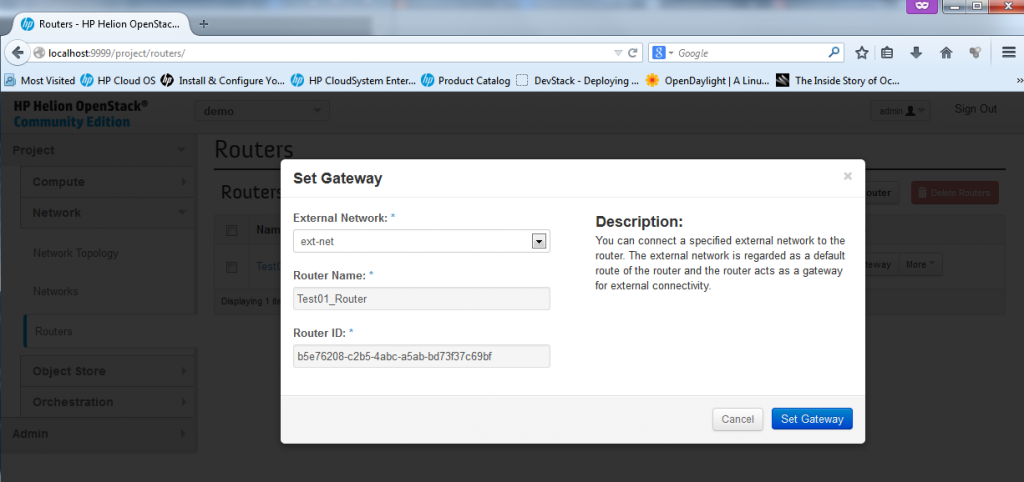
Part 4 – Create New Router – Adding Gateway (or ext-net) interface to a router
This is special, the ext-net network is very special in OpenStack and HP Helion, you cannot simply ad an interface for a router there, adding ext-net implicitelly means that the router has a default route (classical 0.0.0.0/0) to this network. NOTE: In fact, there is no routing configuration possible on these routers! The routers only know directly connected networks and can only route between them, with the only exception with the ext-net where the default route leads once added.
In the routers configuration, simply click on the “Set Gateway” button in the routers list.
![Creating new Router, part 3 - Admin adding interface to a router]()
Creating new Router, part 4 – Admin adding interface to a router
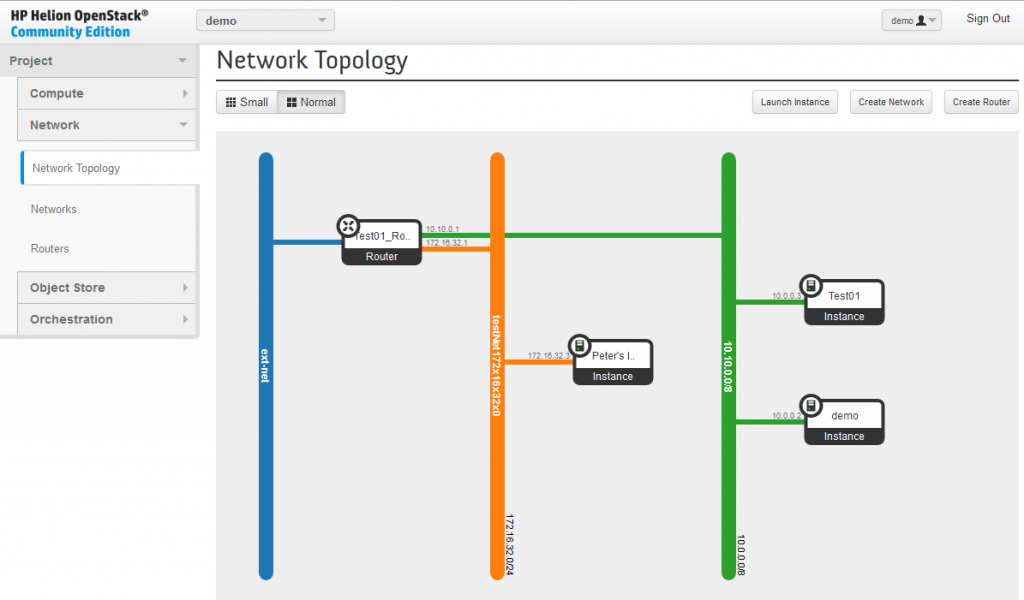
After this last step, you now have a new router that connectes both the default-net and your testNet172x16x32x0 to the outside network of ext-net and the network topology reflects this.
![Creating new Router, part 4 - FINAL new router]()
Creating new Router, part 4 – FINAL new router
NOTE on replacing the default-router (created on installation) with your new test01_Router. If you want, you can delete the default-router from the system and use the new test01_Router instead, just be warned that you MUST remove all existing floating IPs (disassociate them from Instances), then delete the default-router and then you can again associate the IPs back to the Instances. This is because the FloatingIP to real IP NAT is happening on the default-router and you must do this process to move these.
OpenStack Network paths explanation
This I consider the best part of this article, because you are on “networkgeekstuff.com” I wanted to map how all this virtual networks are really forwarded on the network/server levels. And after quite extensive investigation, I now understand it. The HP Helion and the OpenStack components heavily rely on classical unix/linux bridging systems (if you worked with brctl or Open-vSwitch, then you will use these commands here often). Technically these are the basic elemental logical points to keep in mind:
- The virtual “Networks” do not really exist, they are only linux “br-xxx” interfaces on the compute nodes where the individual machine Instances are executed and attached to the networks.
- If two Instances are placed to the same “Network” (means the same “Network” object and subnet like the default-net in our examples), then the compute node can do a bridge between these two Instances.
- The virtual routers and also NAT for FloatingIPs is done depending on where you install the neutron controller, what can be both inside the compute node, or independently on a difference barebone server and this server then becomes a “network node”. If the network node is independent, the traffic from individual Instances (and their compute nodes) has to be tunneled to the network node and routed there.
- Virtual networks between different physical notes, like in our example between the Compute node and Controller/Network node are transported by VXLAN tunnels. Each subnet gets it’s unique VXLAN Network Identifier (VNI) and technically in my example there were just two tunnels. But the important part here to notice is that each packets that needs to get transmitted between different subnets via virtual routers has to cross the VXLAN tunnel connection twice!
To support your understanding of the routing, I also did a quick capture. I have started a ping from both demo (10.0.0.2) and Test01 (10.0.0.3) towards “Peter’s Instance” (172.16.32.3). You can do a capture yourself on the internal network (on the host system, start capturing on all vnet0-4 interfaces), or here is a vnet3 PCAP capture from my test that shows the icmp ping packets. Note: to analyze VXLAN in wireshark, right click and select “Decode as.. ” and select “VXLAN”, wireshark will then analyze also the content of the VXLAN tunnel.
The picture below is showing the whole layer 2 bridged path a packets have to take to communicate either inside one network (default-net has two Instances for this), when crossing between networks (from test01-net to default-net, and reverse) and then from the Instance’s directly connected network (either default-net or test01-net) towards the public/control subnet where the NAT to floating IP is happening as well (click image to enlarge).
![physical_network_forwarding]()
Summary and next-steps …
This is all that I have time to put down at the moment, in summary you now have installed the HP Helion, the HP flagship cloud based on OpenStack and did the essential steps to start using it “as if” a cloud. Just be warned that the HP Helion Community Edition is in NO WAY INTENDED FOR PRODUCTION USE! This comes from the fact that the system is running virtual-in-virtual, this means that on the one single required server, the TripleO is running 4x virtual machines that are “simulating” barebone servers and the OpenStack components like Control Node, Admin Node, Network Node and Compute Node are running virtualized. The Instances for end users are actually virtual machines running above Compute Node as virtual machines inside virtual machine of Compute Node, so this is not really how it should be in production. In real production, the OpenStack components (Control/Compute/Network/Storage/Admin) should all have a dedicated hardware (at least Compute and quite powerful one). So in this regard the HP Helion CE is one step back in contrast to the older public release of HP Cloud OS, which at least basic real deployment.
Hopefully this all will change very soon, this year the HP Helion Enterprise edition should be out and this should provide us with much better LAB environment. For now the HP Helion CE stands as a nice and “quick&dirty” way how to play with the horizon gui, but cannot represent production grade system. If you need production level system, today you have to simply go to some other OpenStack system, or build a vanilla OpenStack environment yourself.
Additionally, the HP Helion Enterprise edition should come with some nice value added software from HP, so I will keep this on my own radar and expect to be reinstalling my LAB from HP Helion CE to the Enterprise edition as soon as available.
PS: This article was basic introduction to OpenStack, if I will have the time, I plan to put together part 2 of this article where we will have a look much deeper under the hood of OpenStack (including packet capture of VXLANs, routing in Network Node and much more).
References